设计模式
学习设计模式?
读这一篇就够了😼。
原则
DRY 原则(Don’t Repeat Yourself)
不要重复你自己
KISS 原则(Keep It Simple, Stupid)
设计需要简约、易用
单一指责原则(Single Responsibility Principle)
一个类,只做一件事,并把这件事做好,其只有一个引起它变化的原因
开闭原则(Open Close Principle)
模块是可扩展的,而不可修改的。也就是说,对扩展是开放的,而对修改是封闭的
里氏代换原则(Liskov Substitution Principle)
子类必须能够替换成它们的基类。即子类应该可以替换任何基类能够出现的地方,并且经过替换以后,代码还能正常工作
依赖倒转原则(Dependence Inversion Principle)
高层模块不应该依赖于低层模块的实现,而是依赖于高层抽象
接口隔离原则(Interface Segregation Principle)
把功能实现在接口中,而不是类中,使用多个专门的接口比使用单一的总接口要好
迪米特法则(Law of Demeter)
最少知道原则
对于对象‘O’中一个方法’M’,M 应该只能够访问以下对象中的方法:
- 对象 O;
- 与 O 直接相关的 Component Object;
- 由方法 M 创建或者实例化的对象;
- 作为方法 M 的参数的对象。
组合复用原则(Composite Reuse Principle)
尽量使用组合 / 聚合,而不是使用继承
好莱坞原则(Hollywood Principle)
Don’t call us, we’ll call you.
所有的组件都是被动的,所有的组件初始化和调用都由容器负责
好莱坞原则就是 IoC(Inversion of Control) 或 DI(Dependency Injection)的基础原则
模式
创建型模式
创建型模式主要对类的实例化过程进行了抽象。
工厂模式(Factory Pattern)
工厂模式一般指简单工厂,使用频率极其高,它封装了对象的创建细节,外部可以通过一个统一的接口来得到自己想要的对象。
抽象工厂模式(Abstract Factory Pattern)
理解抽象工厂的关键在于 “抽象” 2 字,这个抽象其实是 “interface”,用来定义一个负责创建一组产品的接口,就是普通工厂必须实现某个工厂接口,这个工厂接口定义了该类型的工厂可以生产哪些产品。
这个接口内的每个方法都负责创建一个具体产品,如果你限定工厂只生产一种产品,那就只会有一个方法,就退变成普通工厂了,所以抽象工厂的方法经常以工厂方法的方式实现。
比如定义了一个 “电脑工厂”,它定义了 “键盘” 和 “鼠标” 两种产品生产的接口。然后又有 “惠普” 和 “戴尔” 两个具体工厂,实现了 “电脑工厂” 的接口。于是你可以通过具体工厂,完成生产 “键盘” 和 “鼠标” 的操作。至于 “键盘” 和 “鼠标” 到底是如何生产的,由具体的 “惠普” 或者 “戴尔” 内部决定,这个阶段就是工厂模式了。
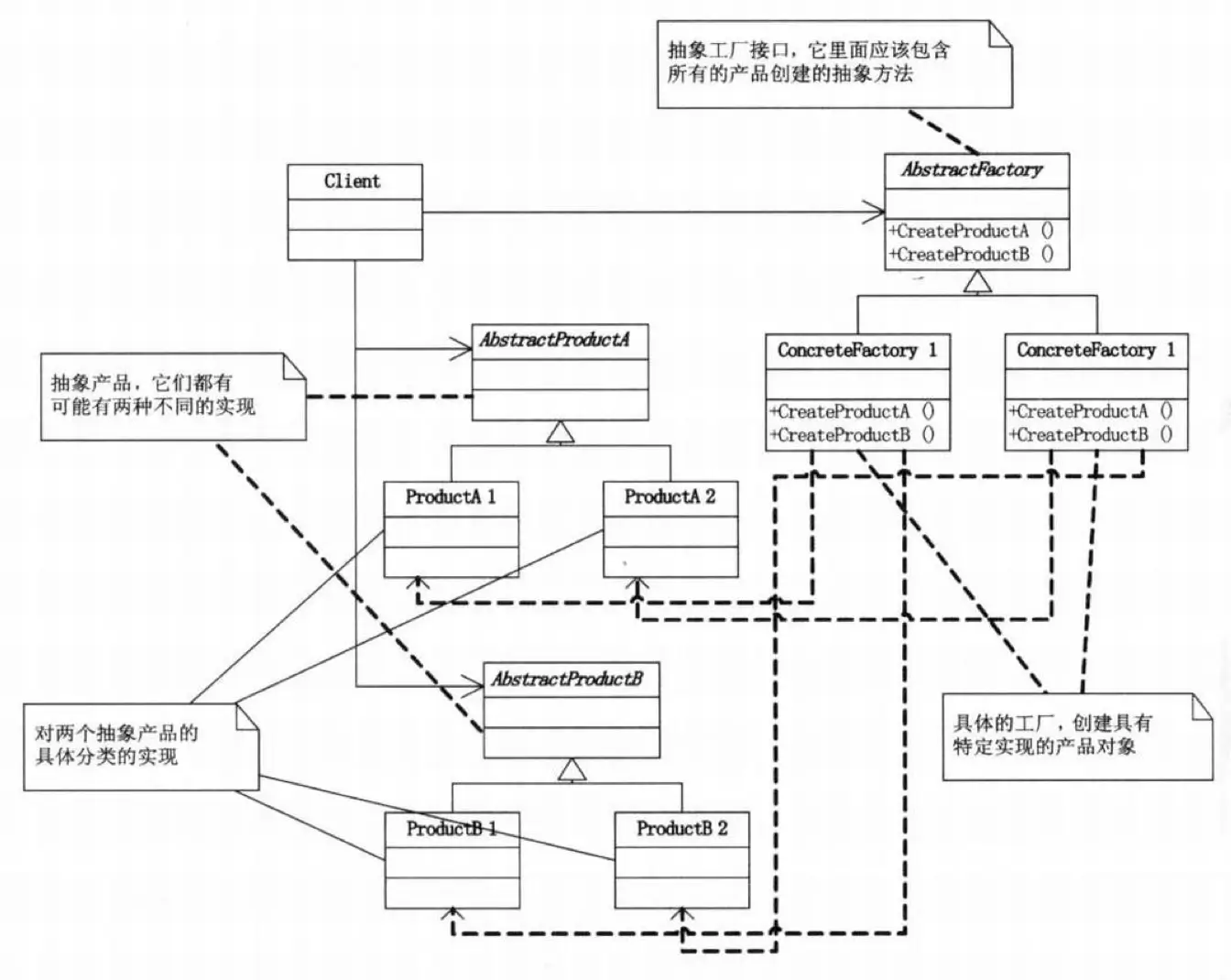
可以看出,抽象工厂在 “产品族” 方面会很方便,比如我新增一个 “华硕” 的产品线,直接新增一个 “华硕工厂” 就行。但是不利于新增产品,比如我新增一个 “显示器” 产品,得所有子工厂都得做修改。
单例模式(Singleton Pattern)
保证一个类仅有一个实例,并提供一个访问它的全局访问点。
但是要值得注意的是,单例模式在多线程编程下得注意线程安全。单例模式的几种常见实现方式都是在线程安全和性能方面权衡:
1. 懒汉式,调用的时候再生成,需要加锁
2. 饿汉式,提前生成准备好,不需要加锁
3. 登记式,其实是懒汉式的升级版本,将静态对象使用 final 来修饰保证线程安全,不需要加锁
当然别忘记限制住外部创建新对象的方式:构造函数、反序列化、克隆等等。
建造者 / 生成器模式(Builder Pattern)
将复杂对象的建造过程抽象出来(抽象类别),使这个抽象过程的不同实现方法可以构造出不同表现(属性)的对象。
这个如果是后端 RD 是肯定会接触到的:ORM。在 ORM 中,不再是手动构建 SQL 语句,而是通过一连串的 select,where,order,limit 调用最终生成 SQL 语句,这个就是生成器模式,很熟悉吧。
原型模式(Prototype Pattern)
用原型实例指定创建对象的种类,并且通过拷贝这些原型创建新的对象。
当一个对象的生成过程很复杂或者会需要消耗非常多的资源,或者因为安全原因被限制了只能获得一个,这个时候使用原型模式可以很低成本的获取一个一模一样的对象。
同时在大部分编程语言中,对象都是引用传递,并不能确保调用者不修改对象里面的某个值,所以可以拷贝一个新的对象传递进去,降低风险。
注意深拷贝和浅拷贝的区别。
结构型模式
结构型模式主要是把对象和类之间组合到更大的结构中 —— 类和对象如何被组合以建立新的结构或功能。
适配器模式(Adapter Pattern)
作为两个不兼容的接口之间的桥梁,使其可以一起工作。通常分为对象适配器和类适配器,对应的就是组合和继承,应该根据适用场景进行选择。

现实生活中各种转接头就是适配器。
桥接模式(Bridge Pattern)
解耦抽象和实现,使其能独立变化。
桥接模式是个比较难的模式,因为它会对设计者的抽象层次要求比较高,同时会增加系统的复杂度,但是它能带来更好的拓展性,它的核心思路是组合。
但是理解之后,就能明白其思路,在各大框架中都能看到它的身影。
网上喜欢用 “画不同颜色的各种形状的图形” 来举例。我在这里换个方式,用大家熟悉的 http 请求来举例。
/**
* 底层请求库抽象
*/
interface requestLib
{
public function request($url, $data);
}
/**
* curl 方式请求实现
*/
class curl implements requestLib
{
public function request($url, $data) {
echo "curl $url with $data";
}
}
/**
* 远程文件方式请求实现
*/
class file implements requestLib
{
public function request($url, $data) {
echo "file_get_contents $url with $data";
}
}
/**
* 远程请求抽象
*/
abstract class request
{
protected $handle;
/**
* 依赖一个 requestLib 抽象,桥接模式体现
*/
public function setHandle(requestLib $handle) {
$this->handle = $handle;
}
abstract public function send($url, $data);
}
/**
* Http 请求实现
*/
class httpRequest extends request
{
public function send($url, $data) {
return $this->handle->request($url, $data);
}
}
class demo
{
public function index() {
$httpRequest = new httpRequest();
//通过 curl 发起一个 http 请求
$httpRequest->setHandle(new curl());
$httpRequest->send('https://www.chengxiaobai.com', 'curl demo');
//通过远程文件方式发起一个 http 请求
$httpRequest->setHandle(new file());
$httpRequest->send('https://www.chengxiaobai.com', 'file demo');
}
}
通过桥接模式模式就把 request (请求类别) 和 requestLib (请求库) 解耦了,这里的关键点是 request 有一个 requestLib 的实现。同理可以推广到其他维度,比如日志维度,logLib (日志记录) 也会有很多种方式,同样需要将它分离出来方便后续拓展。
如果系统可能有多个角度分类,每一种角度都可能变化,把这种多角度分类分离出来,让它们独立变化,减少它们之间耦合,通过桥接模式可以使它们在抽象层建立一个关联关系,这就是桥接模式。
过滤器模式(Filter/Criteria Pattern)
将过滤条件封装起来,方便外部复用和组合。这个模式不复杂,重点在封装和复用的思路,简而言之就是将判定条件封装得更易复用。
这个模式和责任链模式很像,但是不同在于它更侧重判定条件的封装,责任链更倾向于具体功能逻辑的解耦。
比如报警过滤可以用这个模式,当一个异常信息来了,先过滤错误码是否关心,再过滤响应时间是否达到阈值等等,不同报警信息使用不同的过滤条件组合。
组合模式(Composite Pattern)
将对象组合成树形结构以表示” 部分 - 整体” 的层次结构,使得用户对单个对象和组合对象的使用具有一致性。
组合模式对于树形结构特别合适,因为它能屏蔽掉整体上的层级的细节,无论你是在一级目录还是 N 级目录,外部的处理方式都是一样的,所以组合模式的核心是对象接口的理解和确定,一般有 2 种方式:
1. 安全模式,接口只定义基本的行为,树枝节点和叶子结点各自有自己的附加行为。
2. 透明模式,接口定义定义全部的行为,树枝节点和叶子结点对非自己范围内的做空实现,比如删除操作,叶子结点是无法执行删除操作的(这里的删除指删除旗下的某个子结点)。
透明模式遵循了依赖倒转原则推荐使用,安全模式下调用方需求识别到具体的实现类才能进行后续的操作。
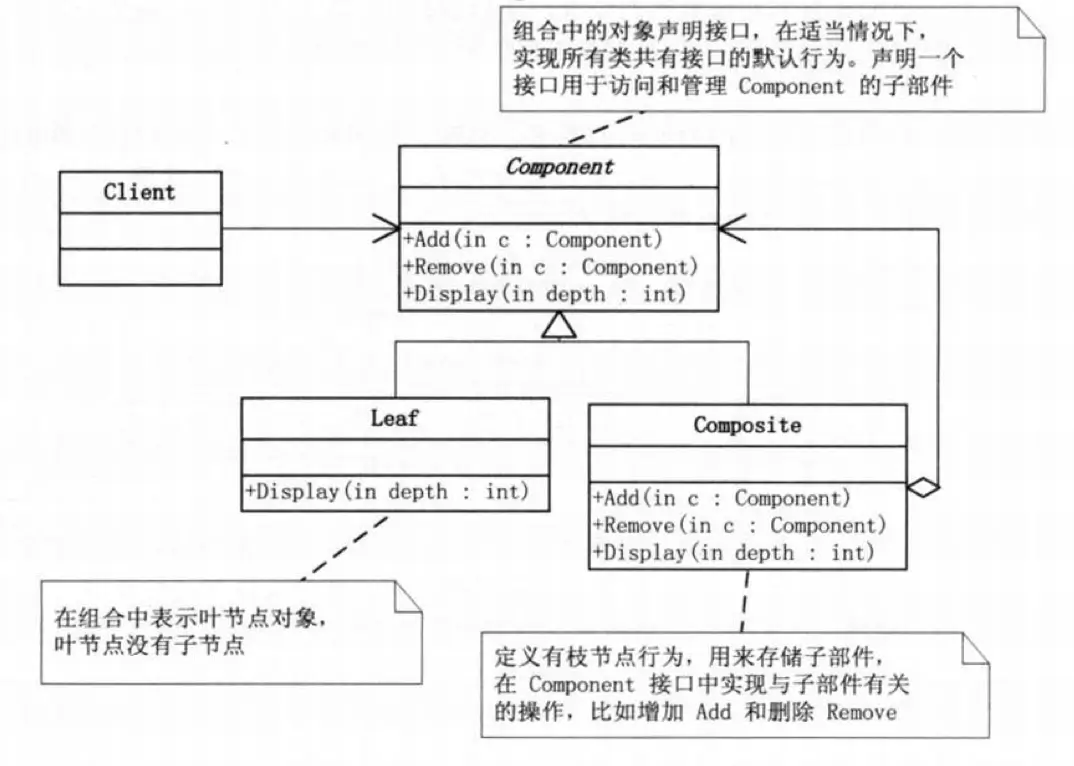
组合模式像 “俄罗斯套娃” 一样,摘一个、套一个很简单,但弊端在于添加新类型的 “娃娃” 很困难,所以利于层级处理,不利于类型拓展。
装饰器模式(Decorator Pattern)
动态的向一个现有的对象添加新的行为。
装饰器模式是一个很赞的模式,它不使用继承,而是通过组合来给对象动态的增减功能,还是拿 http 请求的例子来说吧。
/**
* 远程请求
*/
abstract class request
{
// 这里直接写死 curl 请求方式,与装饰器模式无关,简化步骤
protected $handle = new curl();
abstract public function send($url, $data);
}
/**
* Http 请求
*/
class httpRequest extends request
{
public function send($url, $data) {
return $this->handle->request($url, $data);
}
}
/**
* 远程请求装饰器
*/
abstract class requestDecorator extends request
{
protected $request;
public function __construct(request $request) {
$this->request = $request;
}
}
/**
* Http 请求装饰器,多了一个记录日志的功能
*/
class httpRequestDecorator extends requestDecorator
{
public function send($url, $data) {
$response = $this->request->send($url, $data);
// 记录日志
Log::info($response);
return $response;
}
}
class demo
{
public function index() {
$httpRequestDecorator = new httpRequestDecorator(new httpRequest());
$httpRequestDecorator->send('https://www.chengxiaobai.com', 'demo');
}
}装饰者和被装饰者有着相同的行为定义(它们都实现同一个接口,上面例子使用的是继承抽象类),所以外部调用的时候并不用关注自己调用的是否是被装饰过的对象。如果过度使用,会让系统中出现很多同质的对象,导致复杂度上升,注意控制。
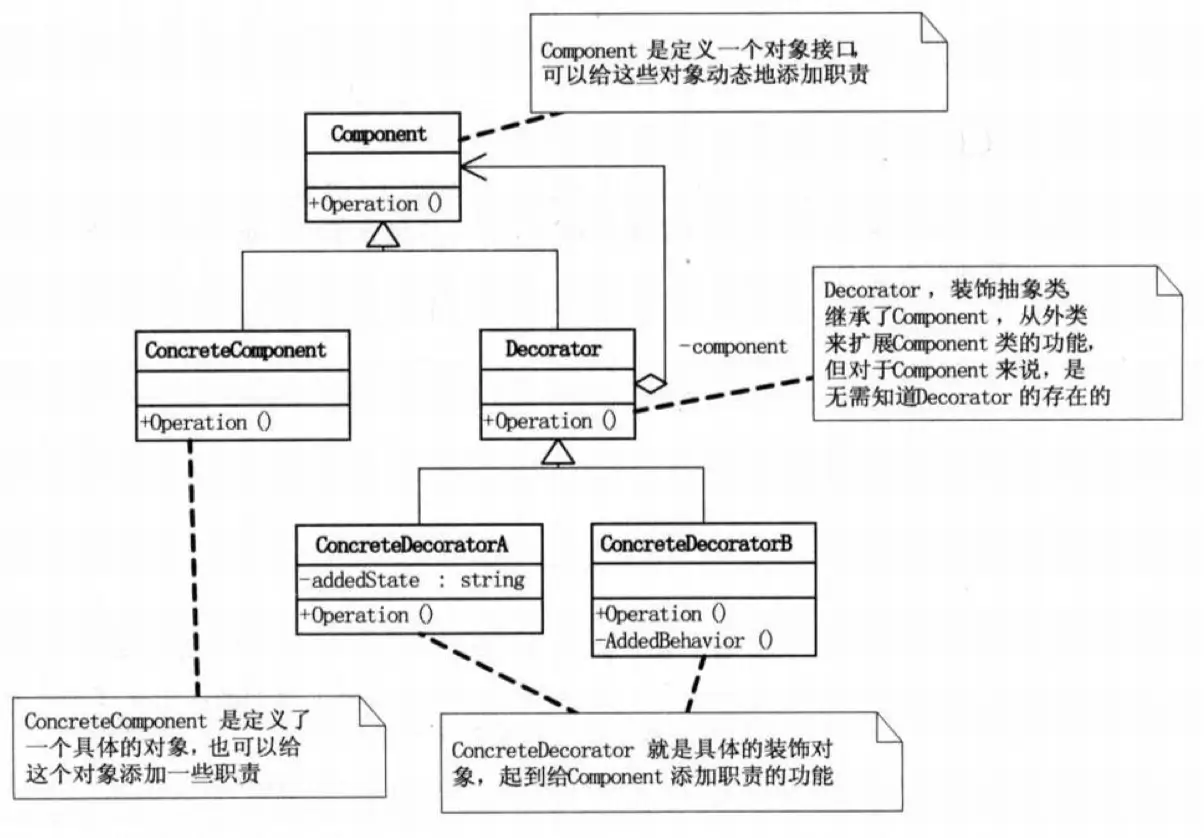
同时装饰模式和代理模式很类似,但是在思想上区别很大,装饰模式是给对象动态的增减功能,代理模式是控制对象的访问,下面马上会说代理模式。
代理模式(Proxy Pattern)
为一个对象提供一个替身或占位符以控制对这个对象的访问。
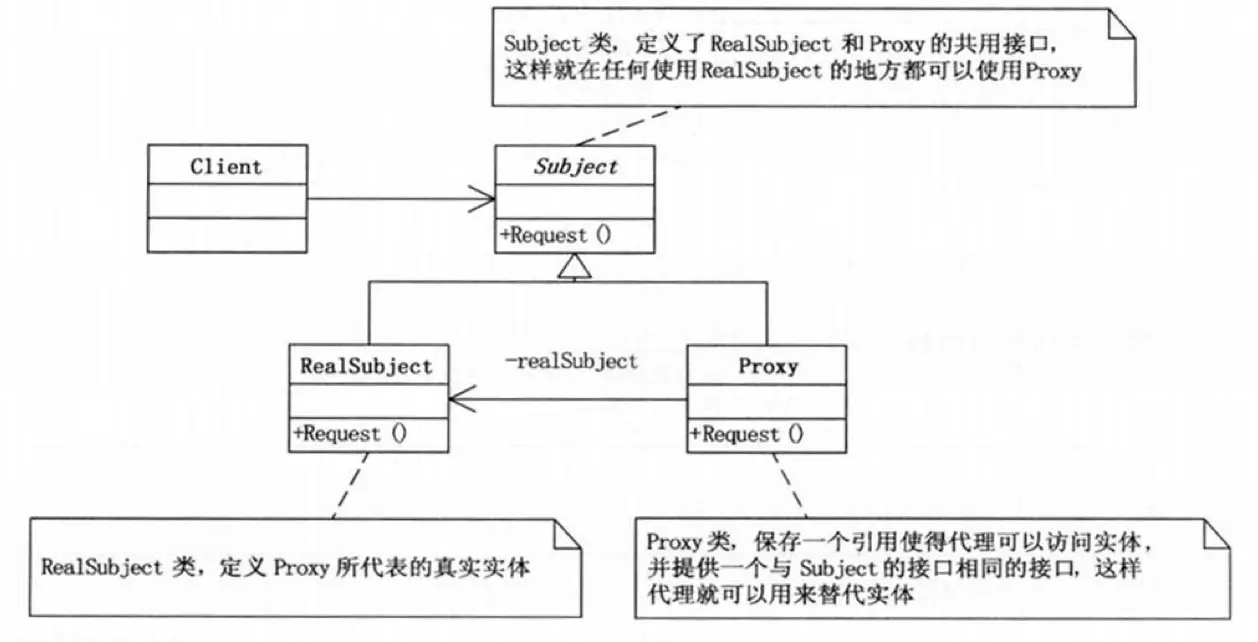
代理模式可以限制、简化、拓展对象的功能,一般一个代理只能代理一个类,并且得保持方法的同步,不然原生对象有了新方法,通过代理却无法正常访问到。
但是这样就会有个问题,会导致代理的数量和复杂度上升,与之诞生了动态代理,之前的方式也被称为静态代理。
在静态代理中,外部调用的每个接口行为,自身都有对应的实现,动态代理则是在被调用的时候在运行过程中生成具体代理对象,然后再执行具体的逻辑的时候再进行操作。
一个是预先定义,一个是延迟生成,性能和灵活性上是有取舍的,不过在可维护性的角度上来说,动态代理更易拓展,各种框架中也都使用的是动态代理,来完成鉴权、延迟加载、单测 Mock 等操作。
cglib 也是动态代理的实现方式之一,不再单独说明。
外观 / 门面模式(Facade Pattern)
为子系统中的一组接口提供一个统一的高层接口,使得子系统更容易使用。
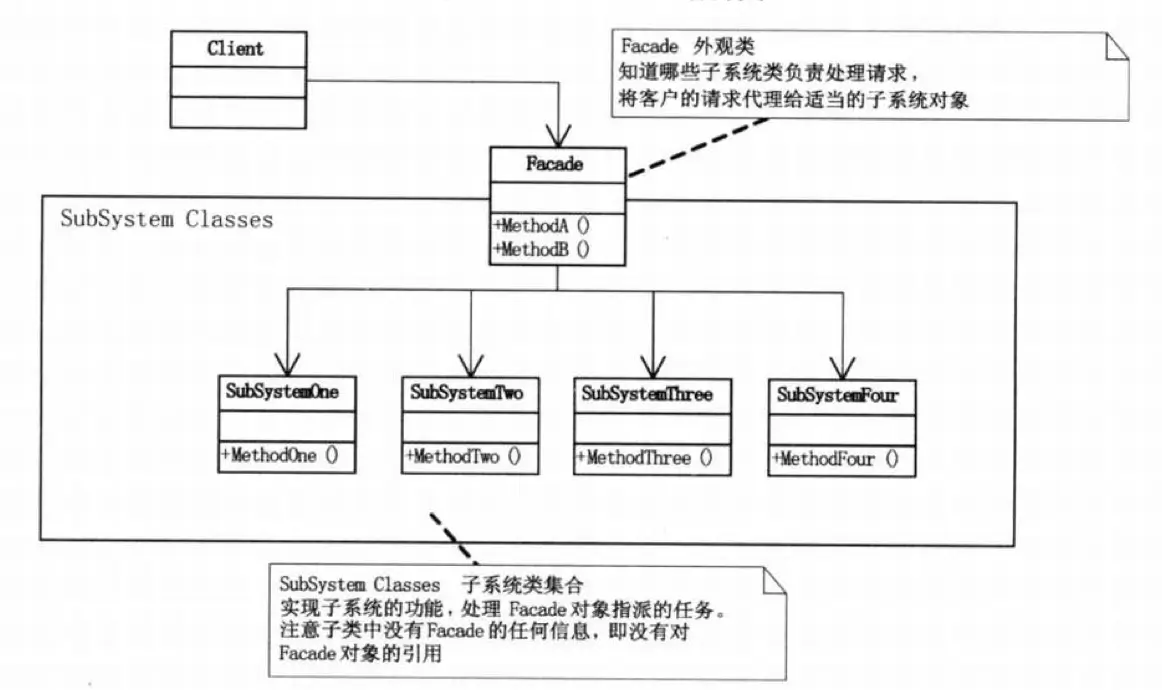
简单说就是封装好一系列的调用流程供外部一键调用,电脑开机、汽车启动、各种一键检测等等功能,就是外观模式了。这个模式只做封装聚合,不应该有太重的逻辑在里面。
享元模式(Flyweight Pattern)
运用共享技术有效地支持大量细粒度的对象。
应该属于一种性能优化方式,思路核心是对应的缓存和复用,具体点的实现就是链接池,该模式重要的是思路。
有些资料划分得更细,把对象的属性(状态)划分成内部状态和外部状态,其实内部状态就是对象自有的、不变的属性,比如对象的唯一 ID,对应的资源 ID;外部状态就是可变的业务属性,比如当前具体的 SQL 语句等。
内部状态就是具有共性的东西,外部状态就是当下业务场景特有的,可以把特有的状态移到外部,在使用的时候再传入进来,尽可能的提高对象的复用率。比如链接池里面的对象就应该只和链接资源有关,使用的时候再将具体的 SQL 语句传入,完成链接对象的使用。
行为型模式
行为型模式重点关注组件之间的交互方式以及职责分配 —— 对象之间的沟通和互联。
责任链模式(Chain of Responsibility Pattern)
构建一条能处理同一类请求的逻辑链条,将待处理对象沿着链条传递。
责任链根据业务需要,可以作为是阻断式的,也可以是非阻断式的。阻断式就是指某个节点处理后,不中止,会继续往下传递,直至走完整个链条节点。
这个模式应用很广泛,比如 Web 框架中常见的中间件,像 Laravel 中的 middleware,或者我之前分析过的 Guzzle 中的请求处理流程,都是责任链模式。
这个模式可以很好的解耦各种业务逻辑间的关系,很方便的拓展节点,同时保持外部调用的简洁性,解耦调用者和具体接受者之间的耦合关系。
注意节点行为的统一性(通过抽象或者接口进行约束),不然会导致节点间无法正常运转。

命令模式(Command Pattern)
将一个请求封装为一个对象,从而使我们可用不同的请求对客户进行参数化:对请求排队或者记录请求日志,以及支持可撤销的操作。
这里的请求不是单单指网络请求,更是一种目标期望:请制作一个披萨、请打开电脑……

这个模式的优点之一就是将 invoker (调用者) 和 receiver (接受者) 解耦了,所以理解这个模式的核心在于调用者和接受者之前关系的理解。
如果没有这俩者存在的情况下,client 也可以直接调用各种 command (命令) 的实现,来完成业务逻辑。但是这样会存在问题:
1.client 需要维护大量的上下文关系,耦合严重。
2. 命令类实现了具体的业务逻辑,导致本身会膨胀不利优化和拓展。
所以调用者解决了问题 1,而接受者解决了问题 2。
client 只对接调用者即可,调用者来完成命令执行的前置处理,包括非法命令校验、日志处理、队列支持等等。
命令来调用接受者,命令本身不实现具体的业务逻辑,而是分发给具体的实现类来完成,有时候某些简单的实现会由命令直接实现,而没有接受者。但是接受者的存在是利于架构的拓展的,因为命令本身是可以依赖于接受者的抽象,而不是具体实现,实现解耦(面向接口编程)。
综合来看,invoker (调用者) 是该模式的关键节点:
client(请求服务) -> invoker(命令发布) -> command(命令执行) -> receiver(真正干活)现实中类比下就是餐馆点菜了,厨房可能是凉菜区、热菜区、主食区…,最后细化到干活厨师:
client(顾客) -> invoker(服务员) -> command(厨房) -> receiver(厨师)解释器模式(Interpreter Pattern)
当有一个语言需要解释执行,井且你可将该语言中的句子表示为一个抽象语法树时,可以用该模式。
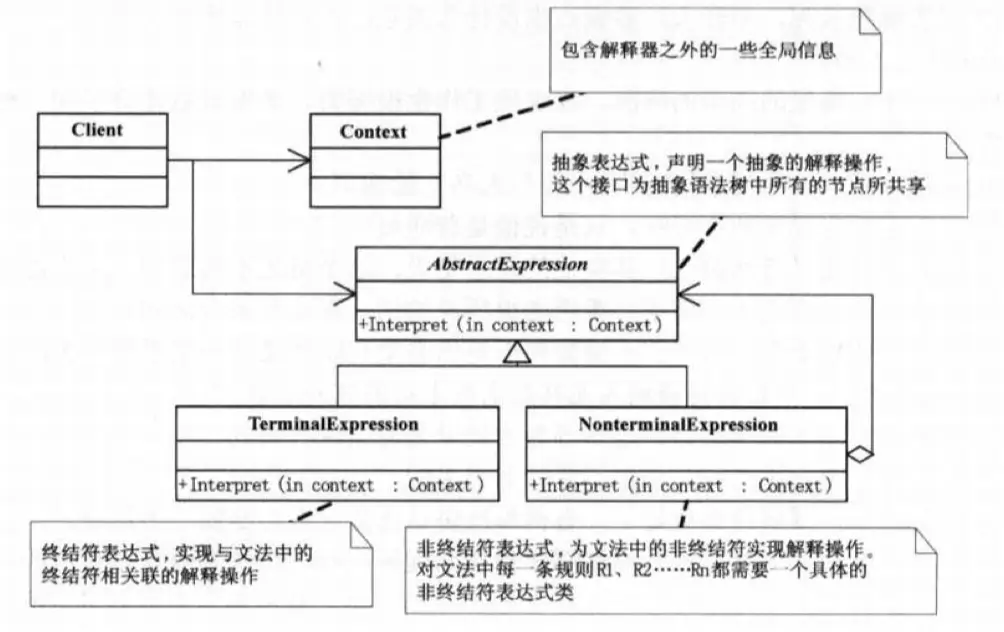
这个模式其实用得蛮多的,但是都是简化版,再复杂就需要上专业的语法分析器和编译器了,像 PHP、JavaScript 这样的解释性语言在运行时候就需要一个解释器,当然其他语言也会有词法分析和编译😂。
为什么说用得多呢?平时解析字符串的过程就是解释器模式的一个简化版。大部分 validation 库比如 prettus/laravel-validation 的校验规则定义:
[
'title' => required|string|len:10,20
]这个就代表了 title 这个字端的校验规则是,它是必传的,并且得是 string 类型,并且长度在 10~20。这个解析规则的过程就是解释器模式的一个实现。
通过这个也很容易看到,这个模式下文法规则可以很容易的拓展,比如我要新增一个 email 类型校验,只用在解析器里面新增一个 email 的校验类即可拓展文法规则:
[
'title' => required|email|len:10,20
]弊端也很明显了,规则解析类的数量和复杂度和文法规则的复杂度成正比,导致在文法规则变复杂的时候,解析类会膨胀到无法维护。
迭代器模式(Iterator Pattern)
提供一种方法顺序访问一个聚合对象中各个元素,而又不暴露该对象的内部表示。
这个模式应用得非常多,就是将对象聚合起来支持不同的方式来遍历对象,所以该模式的关键就是这个起到聚集作用的 “迭代器”。
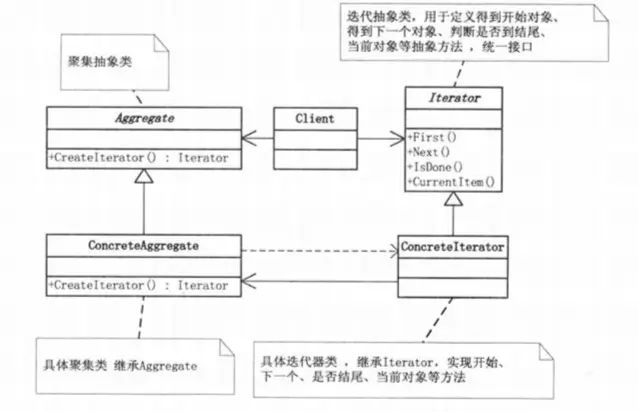
该模式分离了集合对象的遍历行为,抽象出一个迭代器类来负责,这样既可以做到不暴露集合的内部结构,又可让外部代码透明地访问集合内部的数据,它在数组、列表、ORM 库中使用的非常多,以至于大家已经习以为常了。
中介者模式(Mediator Pattern)
用一个中介对象来封装一系列的对象交互,中介者使各对象不需要显式地相互引用,从而使其耦合松散,而且可以独立地改变它们之间的交互。
通常为了提高可复用性,系统内部会被划分为各个组件对象,但是随着系统的规模扩大,组件间的交互又会降低整体的可复用性,所以诞生了一个中介者来封装组件之间的交互,解耦组件间的耦合关系。
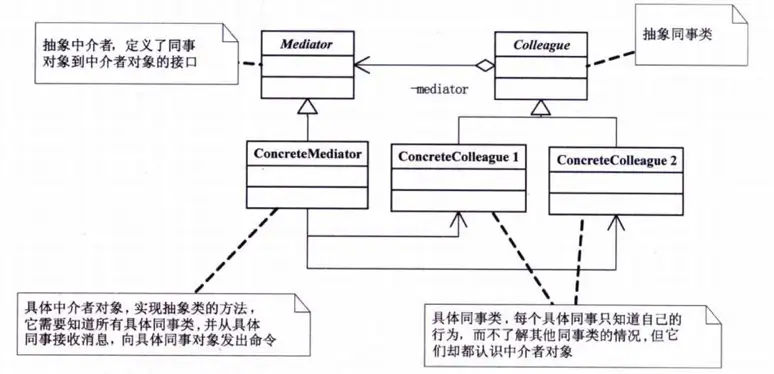
这个模式很好理解,生活中的中介就是这样的模式的一个实现,中心化架构上的 server 也承担着中介者功能比如微信,都是 client to server 而不是 client to client。
从结构上可以知道,中介者将系统的网状结构变成以中介者为中心的星形结构,中介者承担了中转作用和协调作用,但是中介者就变成了一个核心节点,导致其内部逻辑会膨胀降低其维护性。
这个模式和代理模式是有区别的,代理模式归属于结构性模式,主要是控制对象的访问以达到限制、简化、拓展对象功能的目的,并且一般是一对一代理,而中介者模式是可以多对多的,并且主要用来封装对象间的交互。
备忘录模式(Memento Pattern)
在不破坏封装性的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态。这样以后就可将该对象恢复到原先保存的状态。
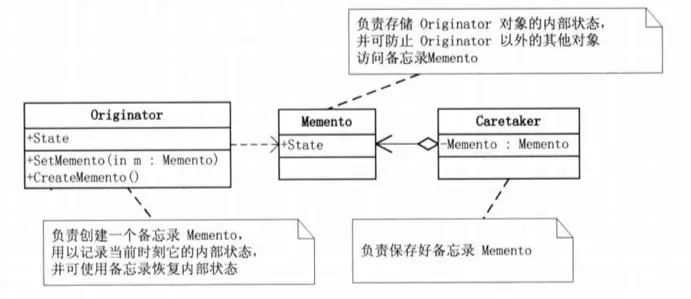
故名思意,当你遇到 “存 / 读档”、“撤销 / 反撤销” 场景的时候,也就是需要保存一些对象的某些属性历史的时候,可以使用该模式。
这个时候存 / 读的逻辑都是由 Originator 自己维护的,由它自己决定存哪些和记录哪些信息。
还记得前面的 [命令模式](# 命令模式(Command Pattern)) 吗?命令模式支持撤销操作,其中就可以使用备忘录模式来存储可撤销操作的状态。
观察者模式(Observer Pattern)
定义了一种一对多的依赖关系,让多个观察者对象同时监听某一个主题对象。这个主题对象在状态发生变化时,会通知所有观察者对象,使它们能够自动更新自己。

这个模式用来解耦对象间的耦合有非常好的效果,它可以让对象各自能独立变改变而不影响其他对象。这个模式的核心在于 “观察” 和 “通知”,观察的是某个主题,主题有了变动之后就会通知那些观察者,观察者就会收到相应的变动信息,所以这个模式也叫 “发布 / 订阅模式”,是不是觉得和消息队列很像?
这个模式的普通版就是 UML 图展示的那样,observer 把自己添加进观察者列表里面,然后主题发生后变化的时候一次调用观察者的方法,来完成通知。
但是有个问题,这样就限制了观察者,它必须实现 observer 接口。但是某个主题可能很重要,观察者来源会很多,无法实现 observer 接口,那样这个模式就有局限了。
委托
上面说了观察者模式普通版的局限,所以有一个高阶版的实现,就是通过委托来解除 observer 行为限制。
一般在项目中委托都是以” 事件委托 “的名号存在,就是很常见的 EventHandler,当然也会有其他叫法,我这里就用这样的叫法来描述。
不同的订阅者可以委托主题的下的某个事件来通知它们,并且告知事件用什么样的方式来通知自己,当主题有变动的时候,会出发响应的事件,然后事件在依次调用自己的委托者列表完成通知。
//委托登记
observer->eventHandler
//委托通知
subject->eventHandler->observer有些框架中会提供事件支持:laravel-event,symfony-event,就是观察者模式的实现,有兴趣可以从各自熟悉的语言框架中了解。
状态模式(State Pattern)
当一个对象的内在状态改变时允许改变其行为,这个对象看起来像是改变了其类。

该模式主要解决的是当控制一个对象状态转换的条件表达式过于复杂时的情况。把状态的判断逻辑转移到表示不同状态的一系列类当中,可以把复杂的判断逻辑简化,所以各种判定逻辑并没有减少,只不过被划分到不同的状态场景下,使得单个类的职责会更清晰。
状态的流转是由各个 status 自己决定的,也就是 context 初始化 statusA 后,statusA 来决定下个状态是哪个,然后交给 context 保管,同时 context 还得维护状态间流转的上下文信息。
空对象模式(Null Object Pattern)
通过一个无实际行为的对象来解决对象引用不存在时引起的问题。
如果一个对象在很多地方都被使用到,都需要对其进行空值判断,就可以使用该模式。它可以减少将 null 当作对象调用时发生的 “空指针” 问题,提高系统的稳定性,同时减少大量的 null 值判定。同时空对象可以不实现具体的业务逻辑,但是可以作为异常检测的一个切入点,记录一些边界异常问题。
不过现在系统一般会有一个默认对象来作为 “兜底” 处理,它比空对象能更好的处理 null 值问题。
策略模式(Strategy Pattern)
定义了算法家族,分别封装起来,让它们之间可以互相替换,此模式让算法的变化,不会影响到使用算法的客户。
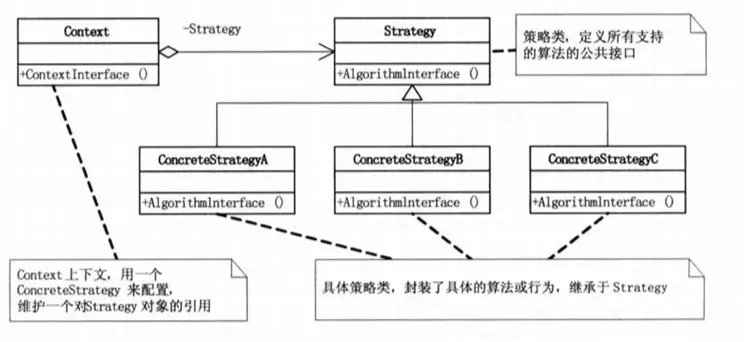
该模式就是用来封装算法的,但在实践中,我们发现可以用它来封装几乎任何类型的规则,只要在分析过程中遇到需要在不同时间应用不同的业务规则,就可以考虑使用策略模式处理这种变化的可能性。
这个模式的普通版就是 UML 图展示的那样,选择所用具体策略的职责是由调用方承担的,这本身并没有解除掉用房需要选择判断的压力。所以一般策略模式需要和 [工厂模式](# 工厂模式(Factory Pattern)) 结合起来使用。
模板模式(Template Pattern)
定义一个操作中的算法的骨架,而将一些步骤延迟到子类中。模板方法使得子类可以不改变一个算法的结构即可重定义该算法的某些特定步骤。
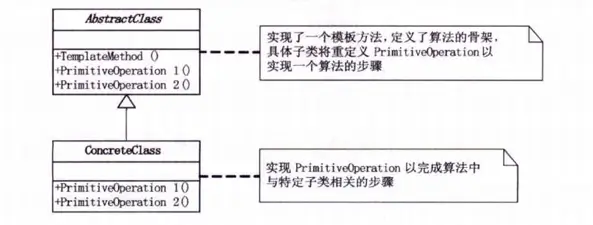
该模式封装了不变的部分,扩展了可变部分,整体的行为由父类控制,子类实现具体的细节。模式不复杂,示例代码就能看懂:
abstract class controller
{
public function index() {
$this->precessBefore();
$this->process();
$this->precessAfter();
}
public function precessBefore() {
Log::info('request start');
}
public function precessAfter() {
Log::info('request end');
}
abstract public function process();
}
class indexController extends controller
{
public function process() {
echo 'Hello World';
}
}很简单的一个 MVC 中 controller 的设计,是不是很简单易懂😄?
访问者模式(Visitor Pattern)
表示一个作用于某对象结构中的各元素的操作。可以在不改变各元素的类的前提下定义作用于这些元素的新操作。
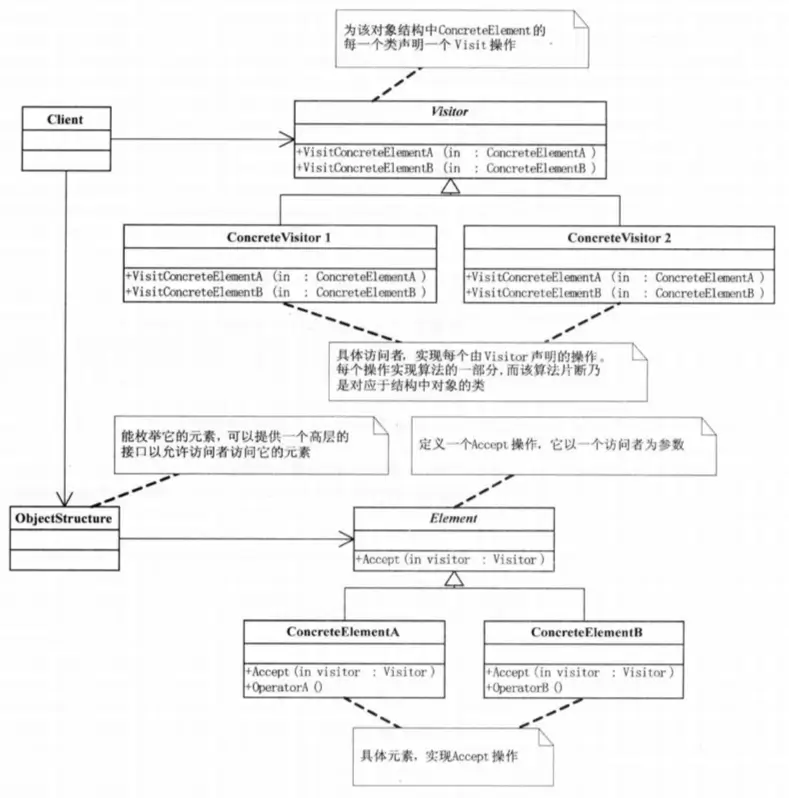
这个模式比较复杂,涉及到了一个” 双分派 “概念,然后因为有些语言比如 Java 支持重载,然后大部分例子又用 Java 来举例,还会涉及到 “静态分派” 和 “动态分派” 概念,更加让人蒙圈。
其实 “静态分派” 和 “动态分派” 也都是相对于某种编程语言才有的,比如 PHP 就不支持重载,就不会有这种概念。
我这里去粗取精,只介绍和本模式相关的概念–” 双分派 “,这样方便对该模式的理解。
双分派
我们先看一段代码
class Content extends Element
{
public function accept(Visitor $visitor) {
// 第二次分派:$this
return $visitor->visitContent($this);
}
public function getInfo() {
return 'This is content text';
}
}
class Admin implements Visitor
{
public function visitContent(Content $content) {
echo $content->getInfo();
echo 'You can edit it';
}
}
class Test
{
public function index() {
$admin = new Admin();
$contentElement = new Content();
// 第一次分派:$admin
$contentElement->accept($admin);
}
}这个就是双分派,第一次分派确定了访问者,第二次确定了被访问者,双分派把访问者和被访问对象组合起来,使得最终的操作由两者共同确定。
你也许觉得下面这样的写法,普通调用(方式二)也能达到相同的目的:
class Test
{
public function index() {
$admin = new Admin();
$contentElement = new Content();
// 方式一
$contentElement->accept($admin);
// 方式二
$admin->visitContent($contentElement);
}
}区别在哪里呢?我们再拓展一个 Comment 来看看。
class Comment extends Element
{
public function accept(Visitor $visitor) {
// 第二次分派:$this
return $visitor->visitComment($this);
}
public function getInfo() {
return 'This is comment text';
}
}
class Admin implements Visitor
{
public function visitContent(Content $content) {
echo $content->getInfo();
echo 'You can edit it';
}
public function visitComment(Comment $comment) {
echo $comment->getInfo();
echo 'You can edit it';
}
}
class Test
{
public function index() {
$admin = new Admin();
$contentElement = new Content();
$commentElement = new Comment();
$elementList = [$contentElement, $commentElement];
// 方式一
foreach ($elementList as $item) {
// 第一次分派:$admin
$item->accept($admin);
}
// 方式二
foreach ($elementList as $item) {
if ($item instanceof Content) {
$admin->visitContent($item);
} elseif ($item instanceof Comment) {
$admin->visitComment($item);
} else {
echo 'error';
}
}
}
}哪个拓展性好一点,不言而喻。
Java 中可能会将
visitContent和visitComment统一修改成visit然后使用重载来完成相应的调用,这个时候重载就会涉及到 “静态分派” 概念。
重载属于 “静态分派”,所以方式二中的instanceof判定逻辑仍然无法移除,所以方式一依旧是最优解。
但是利用重载可以让代码更简洁明了:public function accept(Visitor $visitor) { //return $visitor->visitComment($this); return $visitor->visit($this); }
其实双分派讲完之后,访问者模式就理解一大半了,剩下的就是根据 UML 图补全整个代码框架。
/**
* 元素
*/
abstract class Element
{
abstract public function accept(Visitor $visitor);
abstract public function getInfo();
}
class Content extends Element
{
public function accept(Visitor $visitor) {
// 第二次分派:$this
return $visitor->visitContent($this);
}
public function getInfo() {
return 'This is content text';
}
}
class Comment extends Element
{
public function accept(Visitor $visitor) {
// 第二次分派:$this
return $visitor->visitComment($this);
}
public function getInfo() {
return 'This is comment text';
}
}
/**
* 访问者
*/
interface Visitor
{
public function visitContent(Content $content);
public function visitComment(Comment $comment);
}
class Admin implements Visitor
{
public function visitContent(Content $content) {
echo $content->getInfo();
echo 'You can edit it';
}
public function visitComment(Comment $comment) {
echo $comment->getInfo();
echo 'You can edit it';
}
}
class Stranger implements Visitor
{
public function visitContent(Content $content) {
echo $content->getInfo();
echo 'You can reply it';
}
public function visitComment(Comment $comment) {
echo $comment->getInfo();
}
}
/**
* 结构对象
*/
class ObjectStructure
{
private $elementList = [];
public function addElement(Element $element) {
$this->elementList[] = $element;
}
public function show(Visitor $visitor) {
foreach ($this->elementList as $item) {
// 第一次分派:$visitor
$item->accept($visitor);
}
}
}
/**
* Test Client
*/
class Test
{
public function index() {
$objectStructure = new ObjectStructure();
$objectStructure->addElement(new Content());
$objectStructure->addElement(new Comment());
$objectStructure->show(new Admin());
$objectStructure->show(new Stranger());
}
}从这个模式可以看出,访问者模式适用于数据结构相对稳定的系统,如果元素经常变动,那访问者的接口得对应的增减功能,下属子类均得做相应的修改,这样不符合开闭原则。
但是该模式解除了数据结构和作用于结构上的操作之间的耦合,使得操作集合可以相对自由地
演化。使得增加新的操作很容易,因为增加新的操作就意味着增加一个新的访问者。
上例中 Admin 和 Stranger 对相同数据源的操作就不一样,如果此时需要新增一个粉丝角色:可以管理评论,但是不能修改文章,只用新增一个 Fans 的访问者即可。
写在最后
设计模式(Design Pattern)是一套被反复使用、多数人知晓的、经过分类的、代码设计经验的总结。使用设计模式的目的:为了代码可重用性、让代码更容易被他人理解、保证代码可靠性。设计模式使代码编写真正工程化;设计模式是软件工程的基石脉络,如同大厦的结构一样。
注意,设计模式是经验的总结,经验的背后体验的是一套思路,所以设计模式重要的不是 UML 图,不是代码结构,而是背后的思路和最前面说的各项软件工程原则的体现。
如果学习设计模式只从 UML 和代码结构来学习的话,那就是典型的死记硬背了,套路功夫是没办法实战的。
现在很多语言本身的支持各种动态特性,如果再照搬设计模式,往往会将简单的东西复杂化,如果能理解其背后的思路,结合语言本身的特性和项目架构的实际情况完成系统的设计。
比如说策略模式,真的要创建这么多类吗?PHP 的数组能装匿名函数,直接使用字典就能完成策略的封装,实际的思路是将易变的策略封装起来,让其可以独立变化,但是封装的方式没必要是单独的类。
最后说下设计模式滥用的问题,设计模式是为了封装变化,让各个模块可以独立变化,但是怎么识别变化?
所以说如何避免过度设计,这就要求你深入的理解你的程序所在的领域的知识,了解用户使用你的软件是为了解决什么问题,这样你预测用户的需求才会比以前更加准确,从而避免了你使用设计模式来封装一些根本不会发生的变化,也避免了你忽视了未来会发生的变化从而发现你使用的模式根本不能适应需求的新走向。
所以,在你满足了【知道所有设计模式为什么要被发明出来】的前提之后,剩下的其实都跟编程没关系,而跟你的领域知识和领域经验有关系。
加油吧,少年。