Design Patterns
Learning Design Patterns?
Just reading this should suffice 😼.
Principles
DRY Principle (Don’t Repeat Yourself)
Avoid duplication of effort.
KISS Principle (Keep It Simple, Stupid)
Design should be concise and user-friendly.
Single Responsibility Principle
A class should have only one reason to change, and it should excel at that one task.
Open-Closed Principle
Modules should be open for extension but closed for modification. In other words, they should allow for expansion without altering existing code.
Liskov Substitution Principle
Subclasses must be substitutable for their base classes. In other words, subclasses should be interchangeable with their base classes, and the code should continue to function correctly after substitution.
Dependency Inversion Principle
High-level modules should not depend on low-level module implementations but rather on high-level abstractions.
Interface Segregation Principle
Implement functionality in interfaces rather than classes. It is better to use multiple specialized interfaces than a single general interface.
Law of Demeter
The principle of least knowledge.
For a method ‘M’ in object ‘O’, ‘M’ should only access methods of the following objects:
- Object ‘O’.
- Component Objects directly associated with ‘O’.
- Objects created or instantiated by method ‘M’.
- Objects passed as parameters to method ‘M’.
Composite Reuse Principle
Strive for composition/aggregation over inheritance.
Hollywood Principle
Don’t call us, we’ll call you.
All components are passive, and their initialization and invocation are managed by the container.
The Hollywood Principle forms the foundation of IoC (Inversion of Control) or DI (Dependency Injection).
Patterns
Creational Patterns
Creational patterns primarily abstract the process of object instantiation.
Factory Pattern
The Factory Pattern generally refers to the Simple Factory. It is widely used and encapsulates the details of object creation, allowing external entities to obtain the desired objects through a unified interface.
Abstract Factory Pattern
Understanding the Abstract Factory hinges on the word “abstract.” In this context, “abstract” actually means an “interface” used to define a set of products that a factory is responsible for creating. In other words, a regular factory must implement a specific factory interface, which defines the products that can be produced.
Each method within this interface is responsible for creating a specific product. If you limit the factory to producing only one type of product, you end up with a regular factory. Thus, the methods in the Abstract Factory are often implemented as factory methods.
For example, consider a “Computer Factory” that defines interfaces for producing “Keyboards” and “Mice.” Then, you have concrete factories like “HP” and “Dell” that implement the “Computer Factory” interface. You can use these specific factories to produce “Keyboards” and “Mice.” The specifics of how these products are manufactured are determined internally by “HP” or “Dell,” making this phase the Factory Pattern.
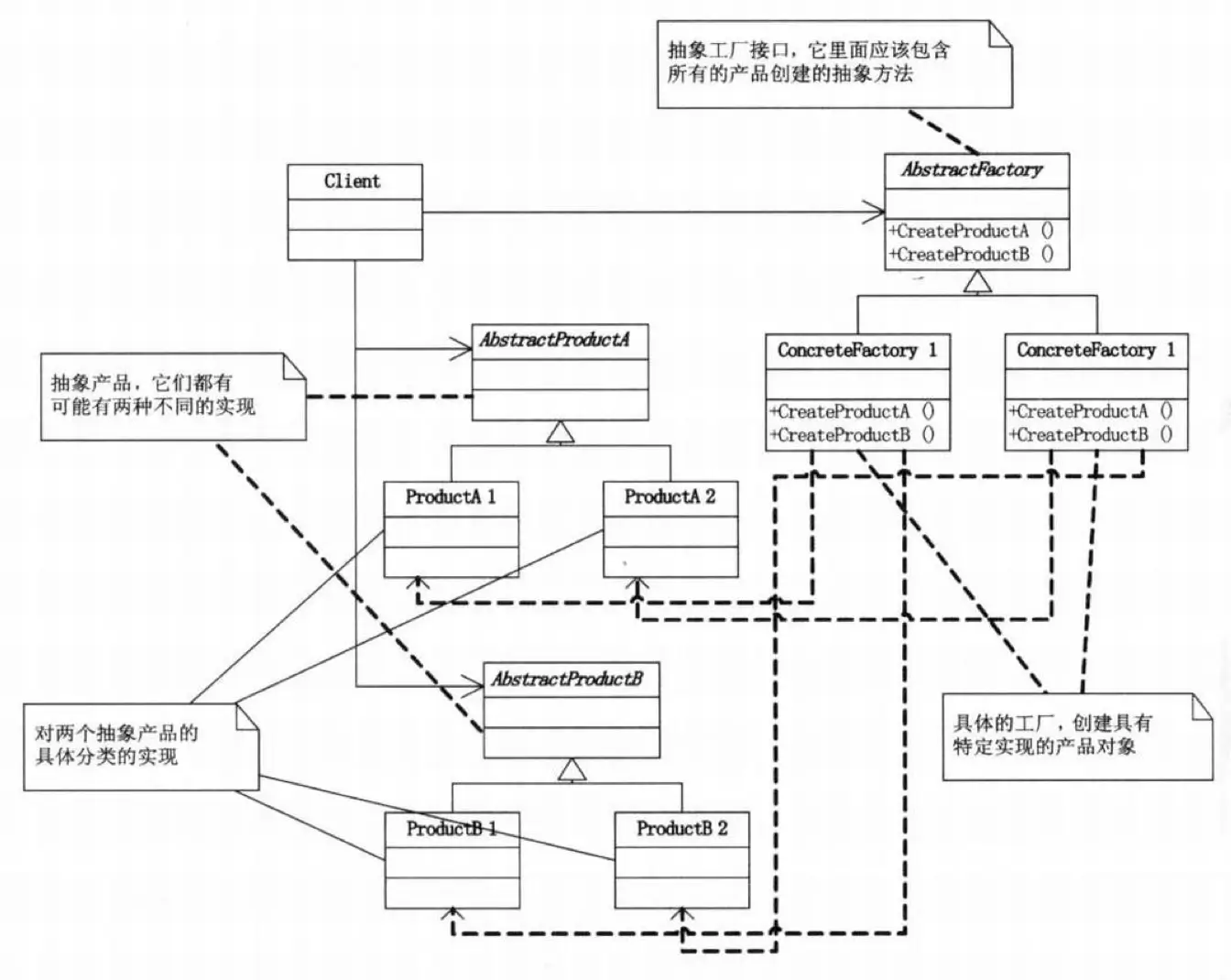
It’s worth noting that the Abstract Factory is particularly convenient for dealing with “product families.” For instance, if you want to add an “Asus” product line, you can simply add an “Asus Factory.” However, it’s less suitable for adding new products. If you want to introduce a new “Monitor” product, you’ll need to modify all the child factories.
Singleton Pattern
It ensures that a class has only one instance and provides a global point of access to it.
However, it’s important to note that the Singleton Pattern requires attention to thread safety in multithreaded programming. Several common implementations of the Singleton Pattern trade off between thread safety and performance:
- Lazy initialization, creating the instance when needed, but requiring synchronization.
- Eager initialization, creating and preparing the instance in advance, without requiring synchronization.
- Registration-based, an enhanced version of lazy initialization using the
finalkeyword for thread safety, eliminating the need for synchronization.
Don’t forget to restrict external creation of new objects through constructors, deserialization, cloning, etc.
Builder Pattern
It abstracts the construction process of complex objects, allowing different implementations of this abstraction to create objects with varying attributes.
If you work on the back end as a software developer, you’re likely to encounter this pattern in the form of Object-Relational Mapping (ORM). In ORM, instead of manually building SQL statements, a sequence of select, where, order, and limit calls generates the final SQL statement. This is the essence of the Builder Pattern and should be quite familiar.
Prototype Pattern
It uses a prototype instance to specify the kinds of objects to create, and new objects are created by copying this prototype.
This pattern is useful when object creation is complex, resource-intensive, or restricted to only one instance for security reasons. It allows you to obtain an identical object at a low cost. In most programming languages, objects are passed by reference, so there is no guarantee that the caller won’t modify an object’s internal state. To mitigate this risk, you can create a new object by copying an existing one. Pay attention to the distinction between deep and shallow copying.
Structural Patterns
Structural patterns focus on composing objects and classes into larger structures, addressing how classes and objects can be combined to form new structures or functionalities.
Adapter Pattern
It serves as a bridge between two incompatible interfaces, allowing them to work together. It is usually divided into Object Adapter and Class Adapter, corresponding to composition and inheritance, respectively. The choice between them depends on the specific use case.
Real-life examples of adapters include various types of adapters and connectors.
Bridge Pattern
It decouples an abstraction from its implementation, allowing them to vary independently.
The Bridge Pattern is challenging because it demands a high level of abstraction from the designer and increases system complexity. However, it offers improved extensibility through composition.
Once understood, the pattern becomes clear, and you can identify it in various frameworks.
Instead of the commonly used “drawing shapes of different colors” analogy, let’s explore it through a familiar example: HTTP requests.
/**
* Abstract request library
*/
interface RequestLib
{
public function request($url, $data);
}
/**
* Implementation using cURL for making requests
*/
class Curl implements RequestLib
{
public function request($url, $data)
{
echo "curl $url with $data";
}
}
/**
* Implementation using file_get_contents for making requests
*/
class File implements RequestLib
{
public function request($url, $data)
{
echo "file_get_contents $url with $data";
}
}
/**
* Abstract remote request
*/
abstract class Request
{
protected $handle;
/**
* Depends on an abstract RequestLib, demonstrating the Bridge Pattern
*/
public function setHandle(RequestLib $handle)
{
$this->handle = $handle;
}
abstract public function send($url, $data);
}
/**
* HTTP request implementation
*/
class HttpRequest extends Request
{
public function send($url, $data)
{
return $this->handle->request($url, $data);
}
}
class Demo
{
public function index()
{
$httpRequest = new HttpRequest();
// Make an HTTP request using cURL
$httpRequest->setHandle(new Curl());
$httpRequest->send('https://www.example.com', 'curl demo');
// Make an HTTP request using file_get_contents
$httpRequest->setHandle(new File());
$httpRequest->send('https://www.example.com', 'file demo');
}
}Through the Bridge Pattern, the “request type” and “request library” are decoupled. The key point here is that Request has a RequestLib implementation. Similarly, this can be extended to other dimensions, such as logging (logLib), which can also have multiple implementation options that need to be separated for future expansion. If your system might have multiple aspects of categorization, each of which may change independently, separating these dimensions to reduce coupling and establishing an association relationship at the abstract level is what the Bridge Pattern accomplishes.
Filter Pattern (Filter/Criteria Pattern)
Encapsulate filtering conditions for ease of external reuse and composition. This pattern, though not complex, focuses on encapsulating and facilitating reuse of judgment conditions. In short, it makes the criteria more reusable.
This pattern bears a resemblance to the Chain of Responsibility pattern. However, the key difference lies in its emphasis on encapsulating filtering conditions, while the Chain of Responsibility leans toward decoupling specific functional logic.
For instance, this pattern can be applied to alarm filtering. When an exception message arrives, it first filters whether the error code is of concern and then checks whether the response time exceeds a threshold, and so on. Different alarm messages use different combinations of filter conditions.
Composite Pattern
Compose objects into tree structures to represent a “part-whole” hierarchy, ensuring consistent usage of individual objects and composite objects by users.
The Composite Pattern is particularly suitable for tree structures because it conceals hierarchical details at the aggregate level. Whether you are at the top-level directory or at an N-level directory, the external handling remains the same. Therefore, the core of the Composite Pattern lies in the understanding and determination of object interfaces, generally with two approaches:
Safe mode: The interface only defines basic behavior, and branch nodes and leaf nodes have their additional behaviors.
Transparent mode: The interface defines all behaviors, and branch nodes and leaf nodes implement empty behaviors for actions outside their scope, such as deletion operations (where deletion refers to removing a specific child node). Transparent mode follows the recommended Dependency Inversion Principle and is used when the calling party needs to recognize specific implementation classes for subsequent operations.
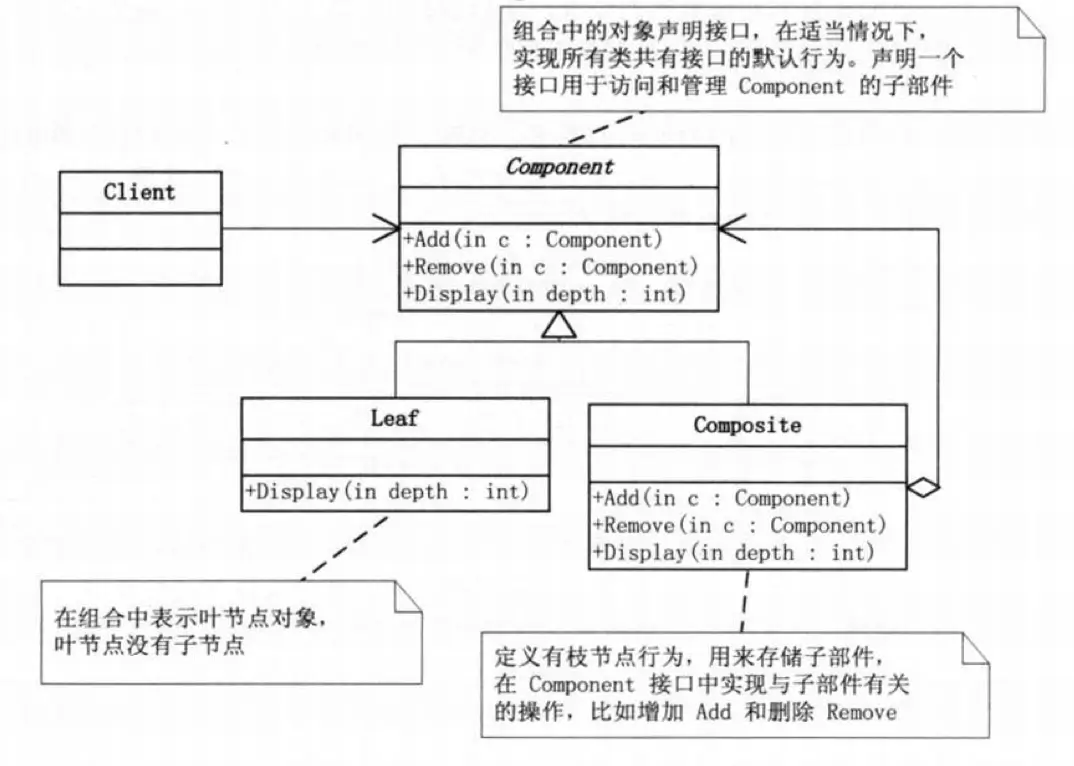
The Composite Pattern is like “Russian nesting dolls” - picking one, nesting one is straightforward. However, the drawback is that adding new types of “dolls” is challenging. It favors hierarchy processing but is not conducive to type extension.
Decorator Pattern
Dynamically add new behaviors to an existing object.
The Decorator Pattern is a remarkable pattern that uses composition rather than inheritance to dynamically add or remove functionality from objects. Let’s continue with the example of HTTP requests:
/**
* Remote request
*/
abstract class Request
{
// Here, we hardcode the cURL request method for simplicity, unrelated to the Decorator Pattern, simplifying the steps.
protected $handle = new cURL();
abstract public function send($url, $data);
}
/**
* HTTP request
*/
class HttpRequest extends Request
{
public function send($url, $data)
{
return $this->handle->request($url, $data);
}
}
/**
* Remote request decorator
*/
abstract class RequestDecorator extends Request
{
protected $request;
public function __construct(Request $request)
{
$this->request = $request;
}
}
/**
* HTTP request decorator with logging functionality
*/
class HttpRequestDecorator extends RequestDecorator
{
public function send($url, $data)
{
$response = $this->request->send($url, $data);
// Log the response
Log::info($response);
return $response;
}
}
class Demo
{
public function index()
{
$httpRequestDecorator = new HttpRequestDecorator(new HttpRequest());
$httpRequestDecorator->send('https://www.example.com', 'demo');
}
}Both the decorator and the decorated object share the same behavior definition (they both implement the same interface, in this example, extending an abstract class). Thus, when externally called, there is no need to worry about whether the called object is decorated or not. However, if overused, it can lead to many homogeneous objects in the system, increasing complexity. It’s essential to maintain control.
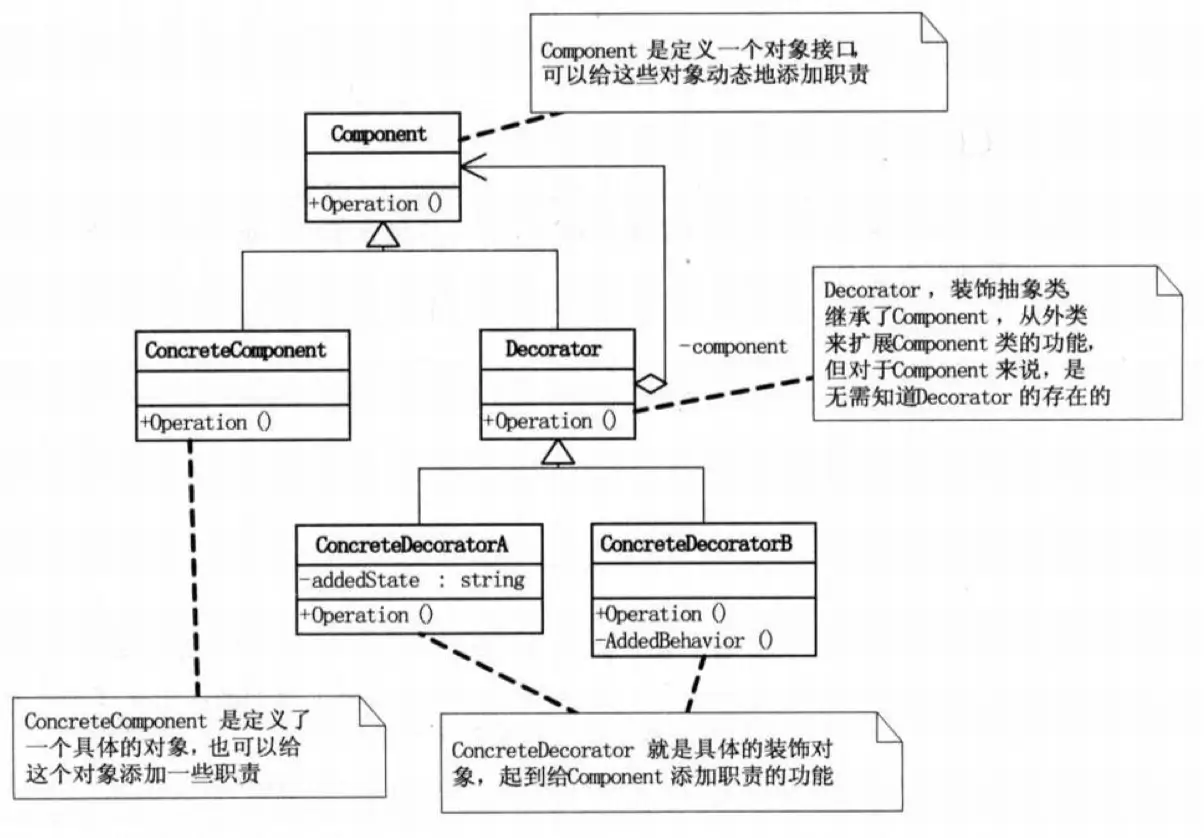
The Decorator Pattern is similar to the Proxy Pattern, but their concepts are significantly different. The Decorator Pattern dynamically adds or removes functionality from objects, while the Proxy Pattern controls object access, as discussed next.
Proxy Pattern
Provide a surrogate or placeholder for another object to control access to that object.
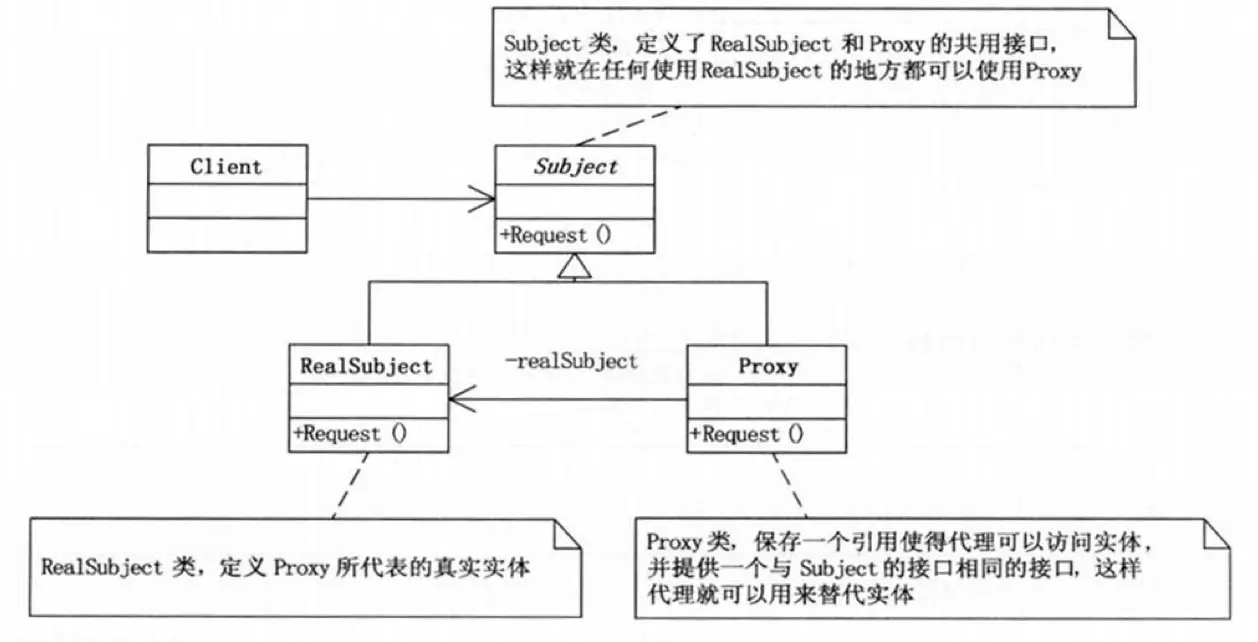
The Proxy Pattern can restrict, simplify, or extend an object’s functionality. Typically, a proxy can only represent one class and must maintain method synchronization. Otherwise, if the original object has new methods, the proxy may not access them correctly.
However, this approach raises concerns about an increasing number and complexity of proxies. Dynamic proxies address this issue. In static proxies, each interface behavior has a corresponding implementation. In dynamic proxies, proxy objects are generated during runtime when they are called, and specific logic is executed during the process.
Static proxies predefine behaviors, while dynamic proxies create objects at runtime and execute specific logic during the process.
Both have trade-offs in terms of performance and flexibility, but from a maintainability perspective, dynamic proxies are easier to extend. Various frameworks utilize dynamic proxies for tasks such as authorization, lazy loading, and unit test mocking.
CGLIB is one of the implementation methods for dynamic proxies but will not be elaborated here.
Facade Pattern
The Facade Pattern provides a unified high-level interface for a group of interfaces within a subsystem, making it easier to use the subsystem.
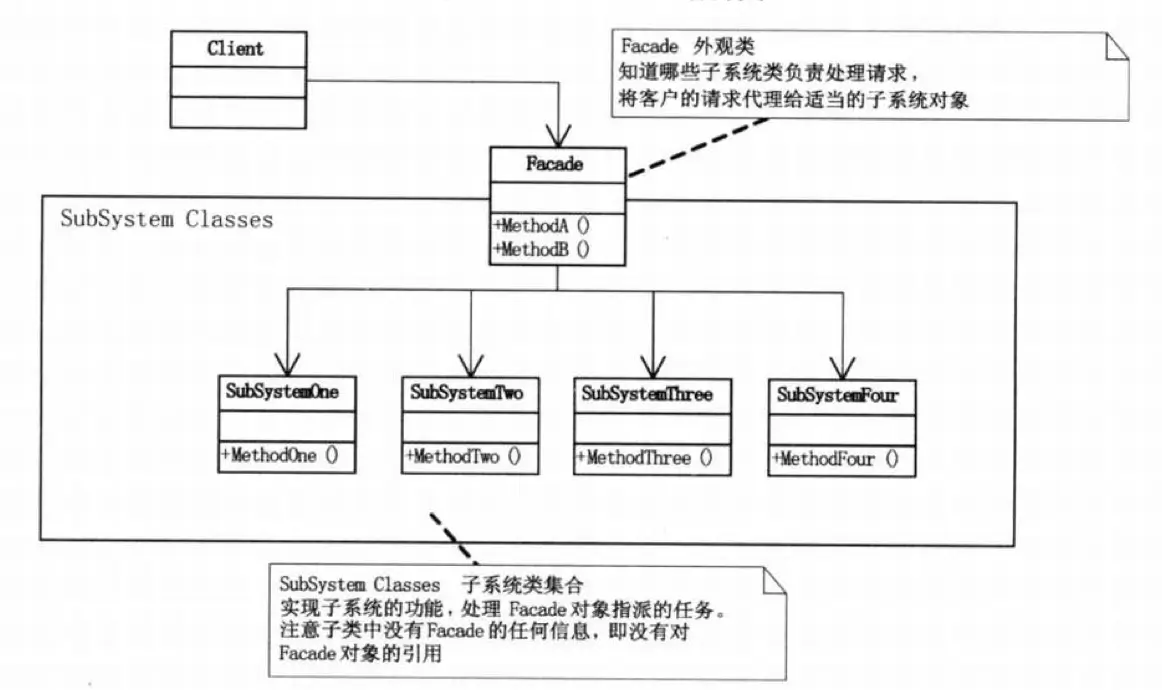
In simple terms, it encapsulates a series of call processes for one-click external access, such as booting a computer, starting a car, and various one-click detection functions. The Facade Pattern is primarily concerned with encapsulation and aggregation and should not contain heavy logic.
Flyweight Pattern
The Flyweight Pattern efficiently supports a large number of fine-grained objects using shared technology.
It should be considered a performance optimization technique, with the core idea being caching and reuse. A specific implementation involves connection pooling, and the key lies in the concept.
Some resources divide object properties (states) into internal states and external states. Internal states are the object’s inherent, unchanging properties, such as a unique ID or a corresponding resource ID. External states are mutable business attributes, such as the current SQL statement.
Internal states represent commonalities, while external states are specific to the current business scenario. Specific states can be moved to the external states, improving object reusability. For example, objects in a connection pool should only be related to connection resources. Specific SQL statements can be passed in when using the objects.
Behavioral Patterns
Behavioral patterns focus on the interaction and responsibility allocation between components - communication and connection between objects.
Chain of Responsibility Pattern
The Chain of Responsibility Pattern constructs a logical chain that can handle the same type of request, passing the object to be processed along the chain.
The Chain of Responsibility can be designed as either blocking or non-blocking, depending on business needs. Blocking implies that, after processing at a node, the request continues to be passed down the chain until it traverses all nodes.
This pattern is widely used, such as in web frameworks with middleware, like Laravel’s middleware, or in Guzzle’s request processing, which are examples of the Chain of Responsibility Pattern.
This pattern effectively decouples various business logics, conveniently extends nodes, and maintains the simplicity of external calls, decoupling the caller and specific receivers.
Ensure uniformity of node behavior through abstraction or interfaces; otherwise, it may lead to the inability of nodes to function correctly.

Command Pattern
The Command Pattern encapsulates a request as an object, allowing us to parameterize clients with different requests, queue requests, log requests, and support undoable operations.
In this context, “request” doesn’t solely refer to network requests; it encompasses various desired actions: ordering a pizza, turning on a computer, etc.
One of the advantages of this pattern is decoupling the invoker (caller) and the receiver (handler). Thus, understanding this pattern revolves around comprehending the relationship between the invoker and receiver.
Without these two, clients can directly call various command implementations to execute business logic. However, this approach has drawbacks:
- Clients need to maintain numerous contextual relationships, resulting in tight coupling.
- Command classes implement specific business logic, making them challenging to optimize and extend.
Therefore, the invoker resolves issue 1, while the receiver resolves issue 2.
Clients only interact with the invoker, which handles pre-execution processing, including illegal command validation, logging, queue support, and more.
Commands call the receiver, not implementing specific business logic themselves but delegating it to concrete classes. Sometimes, simple implementations are directly handled by commands without receivers. However, the presence of receivers aids architectural expansion since commands can rely on the receiver’s abstraction rather than specific implementations, promoting decoupling (object-oriented programming).
In summary, the invoker (caller) is the key component of this pattern:
client (service requester) -> invoker (command issuance) -> command (command execution) -> receiver (actual work)In a real-world analogy, it’s similar to ordering food at a restaurant, where the kitchen may have cold food, hot food, main dishes, etc., each further broken down into individual tasks:
client (customer) -> invoker (waiter) -> command (kitchen) -> receiver (chef)Interpreter Pattern
The Interpreter Pattern is used when there’s a language that needs to be interpreted and executed, and you can represent sentences in that language as an abstract syntax tree.
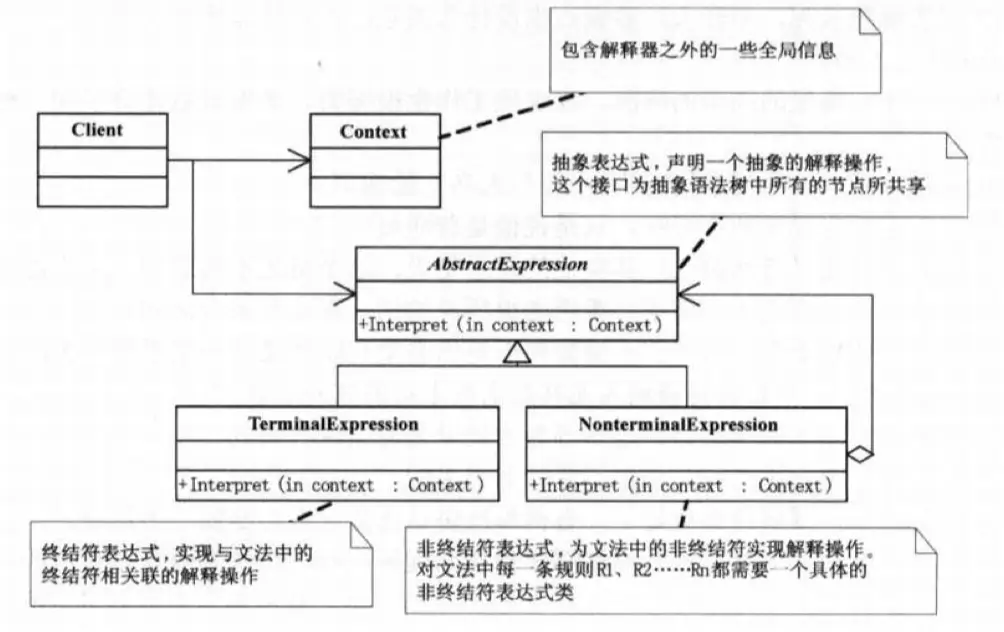
This pattern is widely used, albeit in simplified versions. In more complex scenarios, professional parsers and compilers, like those used in PHP and JavaScript, are necessary. Interpretive languages, such as PHP and JavaScript, require interpreters during runtime. Lexical analysis and compilation are also present in other languages 😂.
Why is it widely used? Everyday string parsing processes are a simplified version of the Interpreter Pattern. Most validation libraries, like prettus/laravel-validation, define validation rules like this:
[
'title' => required|string|len:10,20
]This represents the validation rules for the ‘title’ field: it must be required, a string, and have a length between 10 and 20 characters. This parsing process is an implementation of the Interpreter Pattern.
This also makes it evident that the grammar rules can be easily expanded. For example, if we want to add email validation, we only need to add an email validation class inside the parser to extend the grammar rules:
[
'title' => required|email|len:10,20
]The drawback is clear: the number and complexity of parsing classes are directly proportional to the complexity of grammar rules, making it challenging to maintain when rules become intricate.
Iterator Pattern
The Iterator Pattern provides a way to access elements sequentially in an aggregate object without exposing its underlying representation.
This pattern is prevalent, aggregating objects to support various ways of traversing them. The key to this pattern is the “iterator” acting as an aggregator.
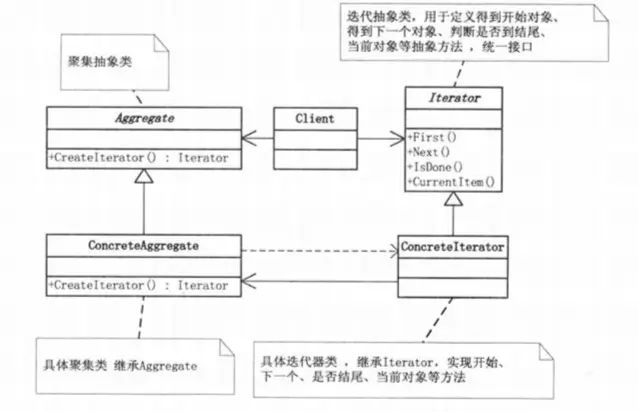
This pattern separates the traversal behavior of collection objects, abstracting it into an iterator class. This approach avoids exposing the internal structure of the collection, allowing external code to transparently access the collection’s data. It’s widely used in arrays, lists, and ORM libraries, becoming so commonplace that it’s taken for granted.
Mediator Pattern
The Mediator Pattern uses a mediator object to encapsulate a series of object interactions. It allows objects to interact without needing explicit references to each other, reducing coupling and enabling independent changes in their interactions.
Usually, to enhance reusability, a system is divided into various component objects. However, as the system grows, interactions between components can reduce overall reusability. Therefore, a mediator is introduced to encapsulate interactions between components, decoupling their relationships.
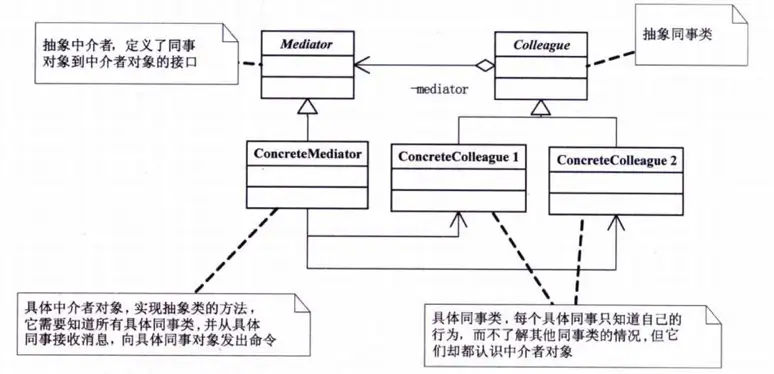
This pattern is straightforward to understand; it mirrors real-life situations with intermediaries. In centralized architectures, servers play the role of a mediator, such as in chat applications like WeChat, where communication is client to server, not client to client.
Structurally, the mediator transforms the system’s mesh-like structure into a star-like structure, with the mediator acting as the central hub for communication. However, this makes the internal logic of the mediator more complex, reducing maintainability.
This pattern is distinct from the Proxy Pattern. The Proxy Pattern belongs to structural patterns, mainly controlling object access to achieve limitations, simplifications, and extensions of object functionality, often involving one-to-one proxy relationships. In contrast, the Mediator Pattern allows many-to-many relationships and primarily serves to encapsulate interactions between objects.
Memento Pattern
The Memento Pattern, without compromising encapsulation, captures the internal state of an object and stores it outside the object. Later, this allows the object to be restored to its previously saved state.
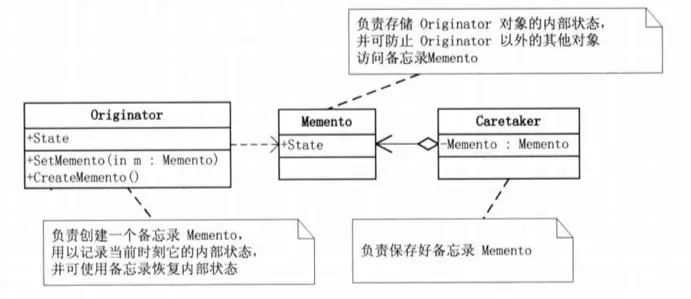
As the name suggests, this pattern is employed in scenarios such as “save/load” and “undo/redo,” where it is necessary to preserve historical attributes of certain object properties.
During such storage and retrieval processes, the logic is maintained by the Originator itself, determining what information should be stored and recorded.
Do you recall the Command Pattern? It supports undo operations, and the Memento Pattern can be used to store the state of actions that can be undone.
Observer Pattern
The Observer Pattern defines a one-to-many dependency between objects, allowing multiple observer objects to simultaneously monitor a subject object. When the subject’s state changes, all observer objects are notified, enabling them to update themselves automatically.

This pattern effectively decouples objects, allowing each of them to change independently without affecting others. The core of this pattern lies in “observation” and “notification.” Objects observe a specific subject, and when the subject undergoes changes, it notifies the observers. Hence, this pattern is also known as the “publish/subscribe” pattern, bearing a resemblance to message queues, wouldn’t you agree?
The standard version of this pattern is as shown in the UML diagram. The observer adds itself to the list of observers and is subsequently notified when changes occur. However, a limitation exists in this approach: observers must implement the observer interface. In scenarios where a subject is significant and there are many potential observers, implementing the observer interface becomes impractical.
Delegation
To overcome the limitations of the standard Observer Pattern, an advanced implementation leverages delegation. Commonly referred to as “event delegation,” this method is prevalent in projects, often under the name “EventHandler” or with similar terms. Different subscribers can delegate themselves to specific events of the subject, specifying how they should be notified. When the subject undergoes changes, the corresponding event is triggered, and each event, in turn, notifies its delegated observers.
// Delegation Registration
observer->eventHandler
// Delegation Notification
subject->eventHandler->observerSome frameworks provide event support, such as laravel-event and symfony-event. These frameworks implement the Observer Pattern. If interested, you can explore these patterns in your preferred programming language framework.
State Pattern
The State Pattern allows an object to alter its behavior when its internal state changes, making it appear as if the object changes its class.

This pattern addresses cases where controlling an object’s state transition conditions becomes overly complex. By transferring the state determination logic to a series of classes representing different states, the complexity of decision-making logic is simplified. Consequently, this approach does not reduce the amount of conditional checks but rather categorizes them into various state scenarios, making individual class responsibilities more evident.
State transitions are decided by each individual state, with the context initializing statusA. statusA then determines the next state, which is entrusted to context for management. Additionally, context maintains contextual information for state transitions.
Null Object Pattern
The Null Object Pattern resolves issues arising from referencing nonexistent objects by introducing an object with no actual behavior.
If an object is used extensively throughout a system and requires numerous null checks, this pattern can be advantageous. It mitigates the occurrence of “null pointer” problems when null values are called as objects, enhancing system stability and reducing excessive null value checks. Moreover, the Null Object can remain devoid of specific business logic while serving as an entry point for exceptional boundary issues.
Modern systems typically employ a default object as a “fallback” to handle null value issues more effectively than the Null Object.
Strategy Pattern
The Strategy Pattern defines a family of algorithms, encapsulates each one, and makes them interchangeable. This pattern allows altering the algorithm independently of clients using it.
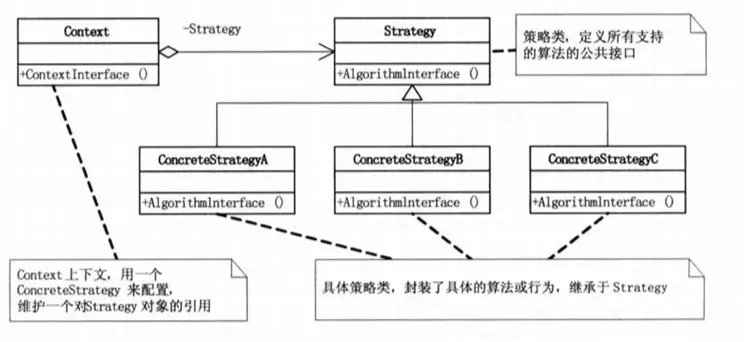
The primary purpose of this pattern is algorithm encapsulation. In practice, it can encapsulate nearly any type of rule. Whenever different business rules may need to be applied at different times during the analysis process, consider using the Strategy Pattern to address the potential changes.
The standard version of this pattern, as shown in the UML diagram, requires the client to assume the responsibility of choosing a specific strategy. This does not alleviate the decision-making burden but rather delegates it to the client. Consequently, the Strategy Pattern is usually used in conjunction with the Factory Pattern.
Template Pattern
The Template Pattern defines the skeleton of an algorithm in an operation, deferring some steps to subclasses. This allows the subclasses to redefine specific steps of the algorithm without changing its structure.
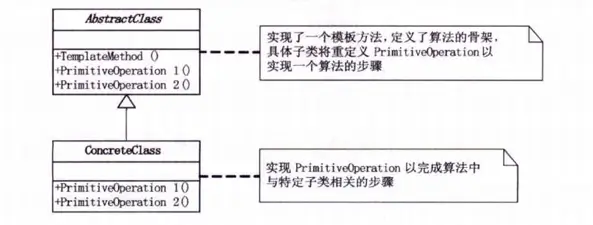
This pattern encapsulates invariant parts while extending variable parts, with the overall behavior controlled by the parent class and fine details implemented by subclasses. The pattern itself is straightforward, as demonstrated in this example:
abstract class controller
{
public function index() {
$this->precessBefore();
$this->process();
$this->precessAfter();
}
public function precessBefore() {
Log::info('request start');
}
public function precessAfter() {
Log::info('request
end');
}
abstract public function process();
}
class indexController extends controller
{
public function process() {
echo 'Hello World';
}
}This design for an MVC controller is simple and easy to understand.
Visitor Pattern
The Visitor Pattern represents an operation to be performed on elements of an object structure. It allows defining new operations without changing the class structure of the elements.
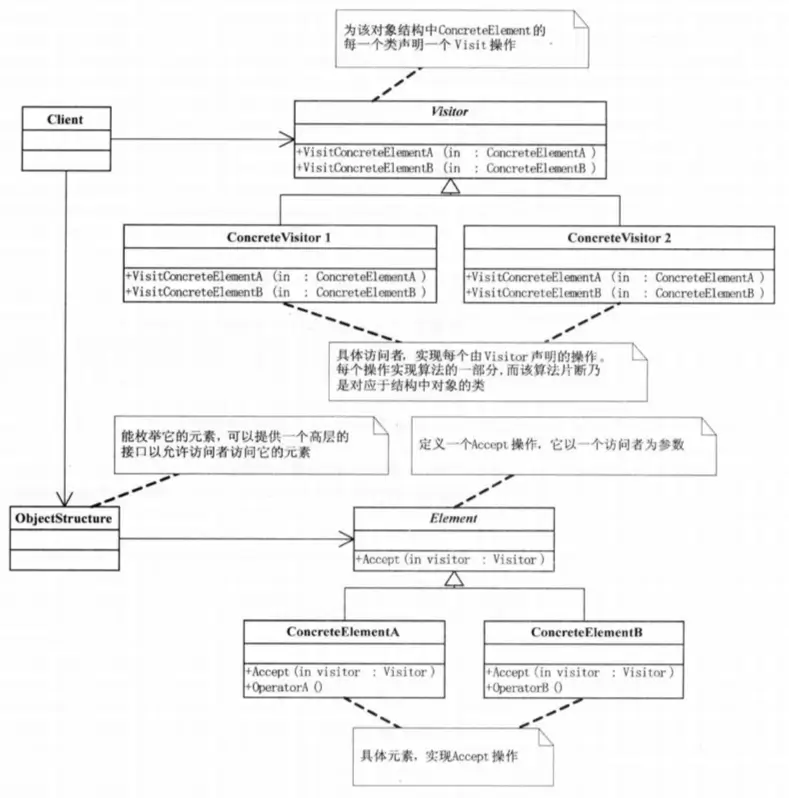
This pattern is relatively complex, involving the concept of “double dispatch.” It can become even more perplexing when illustrated using languages, such as Java, that support method overloading. Many examples feature Java, introducing the notions of “static dispatch” and “dynamic dispatch,” which may cause confusion.
To simplify comprehension, I will focus on the concept of “double dispatch” in the context of this pattern.
Bilateral Dispatch
Let us begin by examining a piece of code:
class Content extends Element
{
public function accept(Visitor $visitor) {
// Second dispatch: $this
return $visitor->visitContent($this);
}
public function getInfo() {
return 'This is content text';
}
}
class Admin implements Visitor
{
public function visitContent(Content $content) {
echo $content->getInfo();
echo 'You can edit it';
}
}
class Test
{
public function index() {
$admin = new Admin();
$contentElement = new Content();
// First dispatch: $admin
$contentElement->accept($admin);
}
}This exemplifies bilateral dispatch, where the first dispatch determines the visitor, and the second determines the visited object. Bilateral dispatch combines the visitor and visited object, allowing both to jointly define the final operation. One might argue that the following approach using regular method calls achieves the same result:
class Test
{
public function index() {
$admin = new Admin();
$contentElement = new Content();
// Approach one
$contentElement->accept($admin);
// Approach two
$admin->visitContent($contentElement);
}
}What distinguishes them? Let’s extend this by adding a Comment to the mix:
class Comment extends Element
{
public function accept(Visitor $visitor) {
// Second dispatch: $this
return $visitor->visitComment($this);
}
public function getInfo() {
return 'This is comment text';
}
}
class Admin implements Visitor
{
public function visitContent(Content $content) {
echo $content->getInfo();
echo 'You can edit it';
}
public function visitComment(Comment $comment) {
echo $comment->getInfo();
echo 'You can edit it';
}
}
class Test
{
public function index() {
$admin = new Admin();
$contentElement = new Content();
$commentElement = new Comment();
$elementList = [$contentElement, $commentElement];
// Approach one
foreach ($elementList as $item) {
// First dispatch: $admin
$item->accept($admin);
}
// Approach two
foreach ($elementList as $item) {
if ($item instanceof Content) {
$admin->visitContent($item);
} elseif ($item instanceof Comment) {
$admin->visitComment($item);
} else {
echo 'error';
}
}
}
}The benefits of extensibility become evident.
In Java, it is common to unify
visitContentandvisitCommentintovisitand use method overloading to achieve the respective calls. At this point, overloading pertains to “static dispatch.” Thus, theinstanceofcheck logic in approach two remains unremovable, making approach one the superior choice.
However, employing overloading can simplify the code:public function accept(Visitor $visitor) { //return $visitor->visitComment($this); return $visitor->visit($this); }
Upon comprehending bilateral dispatch, one can grasp a significant portion of the Visitor Pattern. The remaining task is to complete the code framework according to the UML diagram:
/**
* Element
*/
abstract class Element
{
abstract public function accept(Visitor $visitor);
abstract public function getInfo();
}
class Content extends Element
{
public function accept(Visitor $visitor) {
// Second dispatch: $this
return $visitor->visitContent($this);
}
public function getInfo() {
return 'This is content text';
}
}
class Comment extends Element
{
public function accept(Visitor $visitor) {
// Second dispatch: $this
return $visitor->visitComment($this);
}
public function getInfo() {
return 'This is comment text';
}
}
/**
* Visitor
*/
interface Visitor
{
public function visitContent(Content $content);
public function visitComment(Comment $comment);
}
class Admin implements Visitor
{
public function visitContent(Content $content) {
echo $content->getInfo();
echo 'You can edit it';
}
public function visitComment(Comment $comment) {
echo $comment->getInfo();
echo 'You can edit it';
}
}
class Stranger implements Visitor
{
public function visitContent(Content $content) {
echo $content->getInfo();
echo 'You can reply to it';
}
public function visitComment(Comment $comment) {
echo $comment->getInfo();
}
}
/**
* Object Structure
*/
class ObjectStructure
{
private $elementList = [];
public function addElement(Element $element) {
$this->elementList[] = $element;
}
public function show(Visitor $visitor) {
foreach ($this->elementList as $item) {
// First dispatch: $visitor
$item->accept($visitor);
}
}
}
/**
* Test Client
*/
class Test
{
public function index() {
$objectStructure = new ObjectStructure();
$objectStructure->addElement(new Content());
$objectStructure->addElement(new Comment());
$objectStructure->show(new Admin());
$objectStructure->show(new Stranger());
}
}From this pattern, we can observe that the Visitor Pattern is suitable for systems with relatively stable data structures. If elements frequently change, the visitor’s interface must be adapted accordingly, necessitating adjustments in all subclasses. Such inflexibility contradicts the open-closed principle.
However, this pattern decouples the data structure from the operations applied to it, facilitating the addition of new operations. This entails simply adding a new visitor when a new operation is needed. In the example above, both Admin and Stranger operate on the same data source differently. Introducing a new role, such as a “Fan” who can manage comments but not edit articles, would only require the addition of a Fan visitor.
In Conclusion
Design patterns are a collection of repeatedly utilized, well-known, categorized, and distilled experiences in code design. The purpose of employing design patterns is to enhance code reusability, foster a better understanding of the code among others, and ensure code reliability. Design patterns bring a true sense of engineering to code authoring, forming the fundamental framework of software engineering, much like the structure of a grand edifice.
It is important to emphasize that design patterns are distilled from experience. Behind this experience lies a systematic way of thinking. Therefore, the true value of design patterns lies not in UML diagrams or code structures, but rather in the underlying concepts and their embodiment of the software engineering principles mentioned earlier.
Learning design patterns solely through UML diagrams and code structures is akin to rote memorization, and this approach lacks practical application.
In contemporary programming languages, many dynamic features are available. Blindly applying design patterns can often complicate simple matters. Understanding the underlying principles, coupled with the unique features of the language and the practical context of the project, is essential to achieve a well-rounded system design.
For example, consider the strategy pattern. Is it truly necessary to create an abundance of classes? In PHP, anonymous functions can be stored in arrays, which can serve as dictionaries, providing a straightforward way to encapsulate strategies. The true essence of the strategy pattern is to encapsulate volatile strategies, allowing them to vary independently. However, the means of encapsulation need not always manifest as standalone classes.
Lastly, let’s address the issue of overusing design patterns. Design patterns are intended to encapsulate change, allowing various modules to evolve independently. But how do we identify these changes?
Therefore, the key to avoiding overdesign lies in gaining a deep understanding of the domain knowledge relevant to your program. Understand the problems that users aim to solve with your software.
This way, your predictions about user requirements will be more accurate, helping you avoid the unnecessary use of design patterns to encapsulate changes that will never occur.
It also prevents you from overlooking changes that may arise in the future, rendering your chosen pattern inadequate for the evolving demands.
Consequently, once you have satisfied the prerequisite of understanding why each design pattern was invented, the rest is no longer purely about programming; it is about your domain knowledge and domain experience.
Press on, young one.