Analysis of Guzzle Source Code
Guzzle is an exceedingly potent and steadfast HTTP client. Unlike common cURL encapsulation components, Guzzle employs a variety of request methods internally to execute HTTP requests. Although cURL is the most frequently utilized method, Guzzle offers formidable asynchronous and concurrent capabilities, rendering the construction of an HTTP request remarkably facile and extensible. Presently, Guzzle has been integrated into the core modules of Drupal, attesting to its unwavering reliability. Guzzle currently adheres to the PSR-7 specification, thereby enhancing its extensibility and compatibility. While it was briefly mentioned in a previous refactoring record, it was not analyzed in depth. This time, we intend to introduce some usage examples and conduct an in-depth examination of its underlying implementation principles. If you have any queries, kindly elucidate in the comments as we collectively progress.
Note: To minimize the reading load, only key steps of the source code analysis are presented here.
Environment
This article utilizes Guzzle version 6.3.0, with the content of the composer.json file as follows:
{
"require": {
"guzzlehttp/guzzle": "^6.3"
}
}Configuration
Various configurations of Guzzle are related to HTTP requests, such as whether to track 302 redirects, carry cookies, employ SSL, and timeouts, among others.
Configuration items are passed as an array when creating a client object, and all configurations can be found here. Guzzle provides a default configuration that merges with custom configurations and takes precedence.
public function __construct(array $config = [])
{
$this->configureDefaults($config);
}
private function configureDefaults(array $config)
{
// Custom and default configurations are merged here and assigned to member variables
$this->config = $config + $defaults;
}For example:
$config = [
'allow_redirects' => [
'max' => 5,
'referer' => true,
],
'http_errors' => false,
'decode_content' => true,
'cookies' => true,
'connect_timeout' => 1.5,
'timeout' => 2.5,
'headers' => [
'User-Agent' => 'test client for chengxiaobai.com',
],
];
$client = new \GuzzleHttp\Client($config);You can also pass configurations when building a request, and these configurations will merge with those passed in the constructor and apply only to the current request.
private function prepareDefaults($options)
{
$defaults = $this->config;
// These configurations are assigned to a local variable and only apply to the current request
$result = $options + $defaults;
return $result;
}For example:
$client = new \GuzzleHttp\Client($config);
$client->request('GET', 'https://www.chengxiaobai.com/en/',
[
'allow_redirects' => [
'max' => 1,
'referer' => false,
],
]);Special handler Parameter
The handler parameter is quite distinctive; it must be a closure that takes Psr7\Http\Message\RequestInterface and an array type parameter, and it must return either GuzzleHttp\Promise\PromiseInterface or satisfy Psr7\Http\Message\ResponseInterface upon success.
In an object-oriented description, you must implement an interface like this: Chengxiaobai\handler.
interface Chengxiaobai
{
/**
* handler interface
*
* @param RequestInterface $request
* @param array $options
*
* @return Psr\Http\Message\ResponseInterface | GuzzleHttp\Promise\PromiseInterface
*/
public function handler(Psr\Http\Message\RequestInterface $request,array $options);
}This clarifies the structure of the handler. Let’s examine how the source code parses the handler configuration.
public function __construct(array $config = [])
{
if (!isset($config['handler'])) {
// Create a default handler stack
$config['handler'] = HandlerStack::create();
} elseif (!is_callable($config['handler'])) {
throw new \InvalidArgumentException('handler must be a callable');
}
}It is evident that if a custom handler is specified, Guzzle will forego the default handler stack it provides. Unless you are confident, please refrain from altering it haphazardly.
Here’s an example of customizing a handler to return a 404 response for any request:
$client = new \GuzzleHttp\Client($config);
$response = $client->request('GET', 'www.chengxiaobai.com/en/archives/',
[
'handler' => function (\Psr\Http\Message\RequestInterface $request, array $options) {
return new \GuzzleHttp\Psr7\Response(404);
},
]);
echo $response->getStatusCode(); // 404As previously mentioned, Guzzle itself comes with some handlers. Let’s first see what the default handler stack consists of, without delving into the implementation details within each handler, which will be explained in detail during the request processing phase.
public static function create(callable $handler = null)
{
// Define the underlying request implementation method here
$stack = new self($handler ?: choose_handler());
// The following lines add various Middleware
$stack->push(Middleware::httpErrors(), 'http_errors');
$stack->push(Middleware::redirect(), 'allow_redirects');
$stack->push(Middleware::cookies(), 'cookies');
$stack->push(Middleware::prepareBody(), 'prepare_body');
return $stack;
}Attention to the choose_handler Method. The choose_handler method plays a pivotal role in determining the underlying method for implementing requests. It provides a preliminary understanding of the low-level methods used in Guzzle’s request implementation. In essence, all requests are sent through this method. Carefully scrutinizing the source code comments is crucial.
function choose_handler()
{
$handler = null;
// Determine the preferred cURL method if both concurrent and regular cURL are available
if (function_exists('curl_multi_exec') && function_exists('curl_exec')) {
// Register concurrent cURL as the default request method and regular cURL as the synchronous request method
$handler = Proxy::wrapSync(new CurlMultiHandler(), new CurlHandler());
} elseif (function_exists('curl_exec')) {
// If only one of the two cURL methods exists, prioritize regular cURL
$handler = new CurlHandler();
} elseif (function_exists('curl_multi_exec')) {
$handler = new CurlMultiHandler();
}
// If allow_url_fopen is enabled
if (ini_get('allow_url_fopen')) {
$handler = $handler
// If a handler already exists, register a stream handling handler as well
? Proxy::wrapStreaming($handler, new StreamHandler())
// Otherwise, only use the stream handling handler
: new StreamHandler();
} elseif (!$handler) {
throw new \RuntimeException('GuzzleHttp requires cURL, the '
. 'allow_url_fopen ini setting, or a custom HTTP handler.');
}
return $handler;
}Once the handler is created, several middlewares, also known as middleware, are added to the stack. To simplify, the push function is used with the first argument as a closure and the second argument as a string denoting the middleware’s name. Middlewares mainly consist of closures and may appear complex due to potential nesting. Nonetheless, regardless of the complexity of their structure, their fundamental purpose is to process various request data, and their structural type is similar to Chengxiaobai\handler.
For those who wish to delve deeper into Handlers and Middleware, you can refer to the official documentation here. It is advisable to have a good grasp of closures to better understand their design philosophy.
As you may have noticed from the above source code analysis, the system’s default handlers exist in the form of objects. However, when actually used, they are treated as closures. The closures discussed here are those that truly have an impact, rather than the superficial HandlerStack objects. The “Handling Requests” section later in this analysis will provide more details.
Constructing Requests
In reality, all requests are processed asynchronously. Synchronous requests are simply asynchronous requests constructed with an immediate demand for results, effectively converting them to synchronous requests. However, the construction of asynchronous and synchronous requests is similar, with differences to be explained.
public function request($method, $uri = '', array $options = [])
{
$options[RequestOptions::SYNCHRONOUS] = true;
// requestAsync is asynchronous, but it directly invokes wait to make it synchronous
return $this->requestAsync($method, $uri, $options)->wait();
}The uri Parameter of Requests
If you have defined the base_uri parameter in your configuration, you can use relative addresses. If not, relative addresses are not supported. Guzzle does not validate the final uri parameter until the request is sent, so whether the uri is correct is only determined when the request is made.
private function buildUri($uri, array $config)
{
// For backward compatibility, we accept null, which would otherwise fail in uri_for
$uri = Psr7\uri_for($uri === null ? '' : $uri);
if (isset($config['base_uri'])) {
$uri = Psr7\UriResolver::resolve(Psr7\uri_for($config['base_uri']), $uri);
}
// PSR-7 specification is used here, returning an object that implements UriInterface
return $uri->getScheme() === '' && $uri->getHost() !== '' ? $uri->withScheme('http') : $uri;
}For instance, this would result in an error:
$client = new \GuzzleHttp\Client();
$response = $client->request('GET', '/history.html');
/**
* Output:
* Fatal error: Uncaught GuzzleHttp\Exception\RequestException:
* cURL error 3: <url> malformed (see http://curl.haxx.se/libcurl/c/libcurl-errors.html)
* in /app/vendor/guzzlehttp/guzzle/src/Handler/CurlFactory.php on line 187
*/Detailed rules can be found in RFC 3986, section 2. The official documentation provides some quick examples for better understanding. Here are four scenarios:
The safer approach is to always use absolute paths, but relative paths can be useful when web scraping, depending on your specific needs.
Constructing Requests
Within Guzzle, the request objects used internally are all implementations of Psr\Http\Message\RequestInterface. Consequently, expanding Guzzle becomes relatively straightforward as long as you adhere to the PSR-7 specification.
Here, I would like to remind everyone once again that in modern PHP development, it is advisable to adhere to PSR standards, as it contributes to better collaboration and robust development within the community.
public function requestAsync($method, $uri = '', array $options = [])
{
$request = new Psr7\Request($method, $uri, $headers, $body, $version);
return $this->transfer($request, $options);
}Enriching the Request
The structure of transfer is similar to that of Chengxiaobai\handler.
private function transfer(RequestInterface $request, array $options)
{
// This method will create more specific request objects based on your request type
$request = $this->applyOptions($request, $options);
$handler = $options['handler'];
}applyOptions, as the name suggests, constructs a matching request object based on your configuration. For example, it encodes parameters based on the request type, sets the body (e.g., JSON or stream), and configures headers, among other request details.
Note that the configuration is passed by reference, so any modifications to it will affect subsequent operations.
private function applyOptions(RequestInterface $request, array &$options)
{
// Various checks and modifications to $options; if not covered, a $modify flag is set to indicate the need to rebuild $request
// Method to create a new object
$request = Psr7\modify_request($request, $modify);
return $request;
}If there are no changes to be made, it returns the request as is. However, if there are changes, it constructs a new request object. Pay attention to the required parameters; some are retrieved from $changes, while others come from the original $request object. Essentially, it uses the new value if available and preserves the old one if not.
function modify_request(RequestInterface $request, array $changes)
{
if (!$changes) {
return $request;
}
return new Request(
isset($changes['method']) ? $changes['method'] : $request->getMethod(),
$uri,
$headers,
isset($changes['body']) ? $changes['body'] : $request->getBody(),
isset($changes['version'])
? $changes['version']
: $request->getProtocolVersion()
);
}Introduction to Promises
Regarding promises, it belongs to the guzzlehttp/promises library and is a library worth studying. If the opportunity arises, I will analyze its implementation principles. For now, let’s focus on the process of request implementation.
Upon reviewing the source code, one will find that although Guzzle extensively uses promises and closures, the role of promises remains consistent. At present, you can understand promises as state machines with three states: pending, fulfilled, and rejected.
The following example is just an illustration of how it works. The promise specification has various requirements, as detailed in the Promises/A+ specification. The promise used by Guzzle is an implementation of this specification.
$promise = new Promise(
function () {
echo 'waiting';
},
function () {
echo 'canceled';
}
);
$promise->then(
function () {
echo 'onFulfilled';
},
function () {
echo 'onRejected';
}
)->then(
function () {
echo 'onFulfilled';
},
function () {
echo 'onRejected';
}
);Execution starts from the pending state. If the promise is fulfilled, the onFulfilled function is executed; if rejected, the onRejected function is executed. This sequence continues, and by relying on different states to execute different functions, in combination with HTTP requests that either succeed or fail, without a third state, it becomes easy to understand.
private function transfer(RequestInterface $request, array $options)
{
$handler = $options['handler'];
try {
return Promise\promise_for($handler($request, $options));
} catch (\Exception $e) {
return Promise\rejection_for($e);
}
}In this code, success results in promise_for, and failure results in rejection_for.
Introduction to promise_for
The primary purpose of the promise_for method is to ensure that a promise object is returned. This is because the value after being processed by $handler might be a promise object (as $handler handles it), a response object, or an exception. Therefore, the data needs to be “cleaned” and converted into a promise with a fulfilled state.
function promise_for($value)
{
// If it's already a promise object, return it directly
if ($value instanceof PromiseInterface) {
return $value;
}
// If it's an object with a `then` method, convert it into a promise object
if (method_exists($value, 'then')) {
// If it has methods like `wait`, `cancel`, `resolve`, `reject`, etc., add them as default methods; otherwise, set them to null
$wfn = method_exists($value, 'wait') ? [$value, 'wait'] : null;
$cfn = method_exists($value, 'cancel') ? [$value, 'cancel'] : null;
$promise = new Promise($wfn, $cfn);
$value->then([$promise, 'resolve'], [$promise, 'reject']);
return $promise;
}
// If none of the above conditions are met, return a promise with a fulfilled state
return new FulfilledPromise($value);
}Introduction to rejection_for
In the case of an exception, the code goes to rejection_for. Similarly, it performs “data cleaning” and returns a promise with a rejected state.
function rejection_for($reason)
{
if ($reason instanceof PromiseInterface) {
return $reason;
}
return new RejectedPromise($reason);
}Handler Processing
We continue with the transfer method. Before passing it to promise_for, it first calls a $handler, which is the handler function specified in the configuration. Then, it returns a promise object for external asynchronous calls.
private function transfer(RequestInterface $request, array $options)
{
$handler = $options['handler'];
try {
// Here, the handler function specified in the configuration is called first
return Promise\promise_for($handler($request, $options));
} catch (\Exception $e) {
return Promise\rejection_for($e);
}
}Handling Requests
For the previous section on handler processing, you might be wondering why the handler function is called, as it seems like it starts processing the request immediately.
We’ve previously introduced the data structure of the handler, which is a HandlerStack object. However, when used, it becomes a series of combined closures. But why does a data structure that appears as an object become closures when used?
When attempting to call a function on an object, the
__invoke()method is automatically invoked.
With this premise, let’s take a look at the HandlerStack source code.
Based on the name HandlerStack, we can infer that it’s a “stack” data structure, satisfying the “last in, first out” characteristic.
public function __invoke(RequestInterface $request, array $options)
{
// This function is primarily used to implement Middleware operations
$handler = $this->resolve();
// Below, we will analyze this part
return $handler($request, $options);
}
public function resolve()
{
// Variable caching to optimize performance
if (!$this->cached) {
// The handler here is the low-level method for implementing requests selected previously
// If it doesn't exist, the request cannot be implemented, so we throw an exception to terminate
if (!($prev = $this->handler)) {
throw new \LogicException('No handler has been specified');
}
// Reverse the order to implement the "last in, first out" feature, and call each middleware
foreach (array_reverse($this->stack) as $fn) {
// Middleware registration is in the form of [$middleware, $name]
// So, take the first element, which is the specific implementation, and the second is just the name
// The first call passes in the handler; subsequent calls pass in the result of the previous processing
$prev = $fn[0]($prev);
}
// All processing is completed, so cache it
$this->cached = $prev;
}
return $this->cached;
}Above is a classic middleware model implementation. Laravel implements it slightly differently, mainly using the array_reduce function. However, the principles are largely the same, and understanding the fundamentals will help with any middleware implementation.
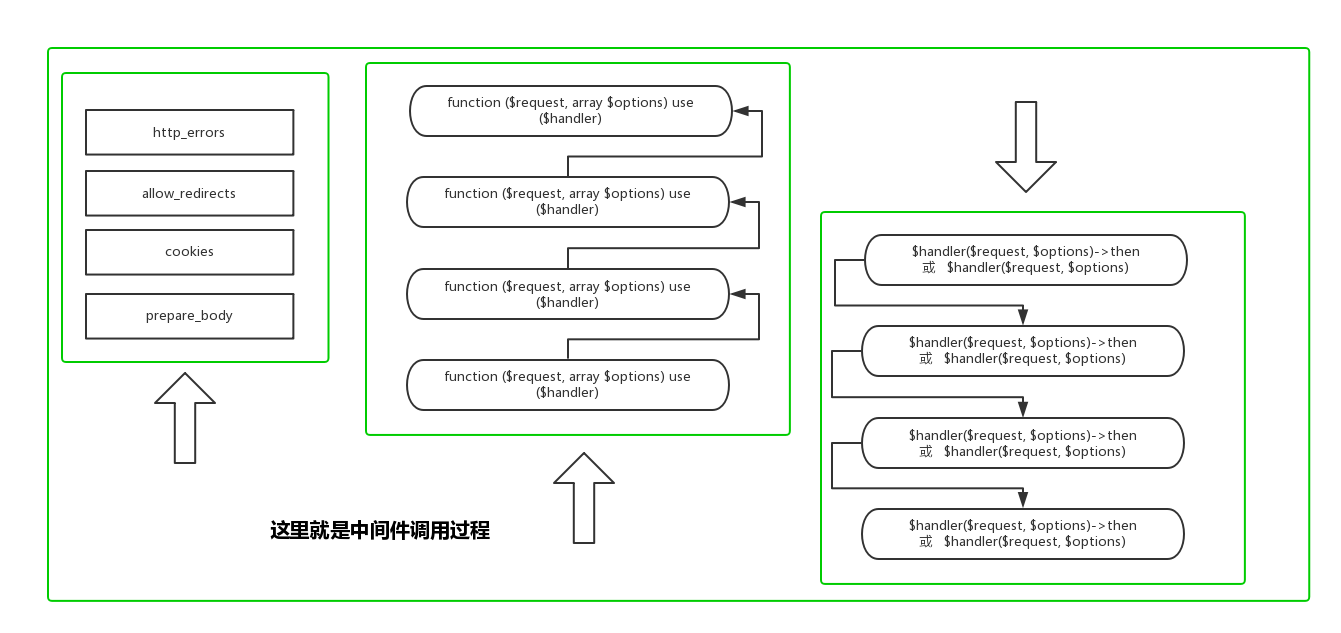
Now, let’s continue with the source code analysis. It’s still the same method, but we’ll analyze the final implementation it calls.
Based on the Middleware flowchart, we know that the last one to be called is http_errors. Let’s analyze it. It’s not particularly special; the structures of other Middleware are the same. Some Middleware use the __invoke() magic method multiple times, but the principles are similar.
Middleware closures have complex structures, so understanding them is essential.
public function __invoke(RequestInterface $
request, array $options)
{
// This function is primarily used to implement Middleware operations
$handler = $this->resolve();
// Now let's analyze this part
return $handler($request, $options);
}
public static function httpErrors()
{
// The first call returns closure-A
return function (callable $handler) {
// The second call returns closure-A, with $request and $options passed in
return function ($request, array $options) use ($handler) {
// Middleware's own logic determines which closure to return
if (empty($options['http_errors'])) {
// The third call returns the result of closure-A's processing
// Here, depending on the configuration, there's no `then` function registered, so the next step is processing
return $handler($request, $options);
}
// The third call returns closure-A, with a promise attached
// Based on the promise features we discussed earlier, here `then` is used to attach the logic to be executed after closure-A finishes processing
return $handler($request, $options)->then(
function (ResponseInterface $response) use ($request, $handler) {
$code = $response->getStatusCode();
if ($code < 400) {
return $response;
}
throw RequestException::create($request, $response);
}
);
};
};
}In regards to the depth of returns, we can quickly identify them based on the presence of the return keyword, with each return corresponding to a single invocation.
Now, let’s organize the number of times handlerStack is invoked so that we can determine where these three layers of closures are called. This will help us arrive at the final result.
// First invocation
public static function create(callable $handler = null)
{
$stack->push(Middleware::httpErrors(), 'http_errors');
}
// Second invocation
public function resolve()
{
$prev = $fn[0]($prev);
}
// Third invocation
public function __invoke(RequestInterface $request, array $options)
{
$handler($request, $options);
}The final result should follow the Middleware structure, something like this:
$handler($request, $options)->then('http_errors')
->then('allow_redirects')
->then('cookies')
->then('prepare_body')Now, which specific request method is $handler referring to? Do you recall the choose_handler() method? It determines which low-level method to use for making the request. Finally, we are at the step of initiating the request.
Let’s review the choose_handler() method.
function choose_handler()
{
$handler = Proxy::wrapSync(new CurlMultiHandler(), new CurlHandler());
$handler = new CurlHandler();
$handler = new CurlHandler();
$handler = $handler
? Proxy::wrapStreaming($handler, new StreamHandler())
: new StreamHandler();
return $handler;
}Each of these different $handler instances is manipulated within the __invoke() method.
Let’s analyze the first one: $handler = Proxy::wrapSync(new CurlMultiHandler(), new CurlHandler());.
public static function wrapSync(
callable $default,
callable $sync
) {
return function (RequestInterface $request, array $options) use ($default, $sync) { // Pay attention to the ternary operator here, checking whether synchronous request options are empty
return empty($options[RequestOptions::SYNCHRONOUS])
// This is the default for concurrent requests, using new CurlMultiHandler()
? $default($request, $options)
// This is for synchronous requests, using new CurlHandler()
: $sync($request, $options);
};
}Now, asynchronous and synchronous requests have finally shown differences. Let’s start with synchronous requests.
Synchronous Requests
Let’s review the request() method, paying attention to one step.
public function request($method, $uri = '', array $options = [])
{
// Here, an option is added to the configuration to mark this request as synchronous
$options[RequestOptions::SYNCHRONOUS] = true;
}So, this code path follows synchronous requests, and we will analyze CurlHandler().
public function __invoke(RequestInterface $request, array $options)
{
// If there's a delay set, it will block here for a while
if (isset($options['delay'])) {
usleep($options['delay'] * 1000);
}
// Create an abstract handler
$easy = $this->factory->create($request, $options);
// Execute the request
curl_exec($easy->handle);
$easy->errno = curl_errno($easy->handle);
// Request processing completed
return CurlFactory::finish($this, $easy, $this->factory);
}Here, we need to analyze the CurlFactory class. Most of the code inside it involves various cURL configurations. If you’re interested, you can review the source code to learn more. The meanings of these configurations are documented in the official documentation. I won’t go into the details of these configurations here. We will focus on the main processing logic.
public function create(RequestInterface $request, array $options)
{
if (isset($options['curl']['body_as_string'])) {
$options['_body_as_string'] = $options['curl']['body_as_string'];
unset($options['curl']['body_as_string']);
}
// Create an abstract handler
$easy = new EasyHandle;
$easy->request = $request;
$easy->options = $options;
// Get the default configuration
$conf = $this->getDefaultConf($easy);
// Parse the request method
$this->applyMethod($easy, $conf);
// Parse the configuration
$this->applyHandlerOptions($easy, $conf);
// Parse headers
$this->applyHeaders($easy, $conf);
unset($conf['_headers']);
// Parse custom cURL configurations
if (isset($options['curl'])) {
$conf = array_replace($conf, $options['curl']);
}
// Set a callback function for handling headers
$conf[CURLOPT_HEADERFUNCTION] = $this->createHeaderFn($easy);
// Get a handle from the handle pool or create a new one
$easy->handle = $this->handles
? array_pop($this->handles)
: curl_init();
curl_setopt_array($easy->handle, $conf);
return $easy;
}
public static function finish(
callable $handler,
EasyHandle $easy,
CurlFactoryInterface $factory
) {
// This calls the on_stats function configured in the options
if (isset($easy->options['on_stats'])) {
self::invokeStats($easy);
}
// If there are errors, follow the error handling process
if (!$easy->response || $easy->errno) {
return self::finishError($handler, $easy, $factory);
}
// Release resources and return to the handle pool
$factory->release($easy);
// Handle stream data
$body = $easy->response->getBody();
if ($body->isSeekable()) {
$body->rewind();
}
// Return a promise in a fulfilled state
return new FulfilledPromise($easy->response);
}Based on the source code analysis, for synchronous requests, the request is sent here, and the on_stats function configured in the options is also called. The unprocessed raw response value is obtained. Also, synchronous request handlers are pooled, meaning that only three request handles are reused, and this number is hardcoded into the code.
Asynchronous Requests
public function __invoke(RequestInterface $request, array $options)
{
$easy = $this->factory->create($request, $options);
// Generate an ID for each request
$id = (int) $easy->handle;
// Register a promise, including execution and close methods
$promise = new Promise(
[$this, 'execute'],
// Close the request based on the ID
function () use ($id) { return $this->cancel($id); }
);
// Add the request, including processing delayed execution requests
$this->addRequest(['easy' => $easy, 'deferred' => $promise]);
return $promise
;
}The CurlFactory class was analyzed earlier and won’t be repeated here. However, asynchronous requests do not actually send the request at this stage. Instead, they generate an ID for each request, add the request to a batch processing session handle (curl_multi_add_handle), and return a promise object. This promise object is configured with an execute function and a cancel function for later request execution and closing. Delayed execution of requests is also handled in the addRequest() method, which will be discussed later in the “Returning Results” section.
Stream Processing
If the stream option is not empty in the configuration, it will be activated. If you don’t have cURL, then this is your only option.
public function __invoke(RequestInterface $request, array $options)
{
// If a delay is set, it will block here for a while
if (isset($options['delay'])) {
usleep($options['delay'] * 1000);
}
// Stream processing itself provides limited information, so to add some context, we record the start time here
$startTime = isset($options['on_stats']) ? microtime(true) : null;
try {
// We don't support the 'expect' header
$request = $request->withoutHeader('Expect');
// When the content size is 0, we still add a header
if (0 === $request->getBody()->getSize()) {
$request = $request->withHeader('Content-Length', 0);
}
// Send the request and then invoke the on_stats function
// Parse the result and return a promise that meets the status
return $this->createResponse(
$request,
$options,
$this->createStream($request, $options),
$startTime
);
} catch (\InvalidArgumentException $e) {
throw $e;
} catch (\Exception $e) {
// Determine if the error was a networking error.
$message = $e->getMessage();
// This list can probably get more comprehensive.
if (strpos($message, 'getaddrinfo') // DNS lookup failed
|| strpos($message, 'Connection refused')
|| strpos($message, "couldn't connect to host") // error on HHVM
) {
$e = new ConnectException($e->getMessage(), $request, $e);
}
$e = RequestException::wrapException($request, $e);
$this->invokeStats($options, $request, $startTime, null, $e);
return \GuzzleHttp\Promise\rejection_for($e);
}
}Regarding stream processing, because its underlying implementation uses the fopen() function, it supports various protocols beyond just HTTP. You can see the full list of supported protocols and wrapper protocols here. Therefore, Guzzle has made some special handling to fulfill specific business needs.
Returning Results
Based on the previous analysis, we already know what the transfer method returns and now we are going to get the results.
Synchronous Requests
For synchronous requests, because the actual request has been sent out and the raw, unprocessed response has been obtained in the transfer method.
public function send(RequestInterface $request, array $options = [])
{
// We notice that the 'wait' method is called at the end
return $this->sendAsync($request, $options)->wait();
}In the synchronous request method, the wait() method is called directly. Therefore, it proceeds to the wait() method of the promise object and the registered then() methods. Do you recall the then() methods registered earlier in the Middleware? This is where they are primarily invoked, completing the “Processing Response” middleware step. Of course, there are also some then() methods registered in the logic processing, which won’t be given as examples here.
Asynchronous Requests
For asynchronous requests, the transfer method returns a Promise, and at this point, the actual request has not been sent yet. Let’s analyze how to send the request and get the response based on an official example.
$promise = $client->requestAsync('GET', 'https://www.example.com');
$promise->then(
function (ResponseInterface $res) {
echo $res->getStatusCode() . "\n";
},
function (RequestException $e) {
echo $e->getMessage() . "\n";
echo $e->getRequest()->getMethod();
}
);In this approach, a then() method is registered separately for each asynchronous request to handle what happens when the request succeeds or fails.
$client = new Client(['base_uri' => 'https://www.example.com']);
// Register multiple asynchronous requests for concurrent execution
$promises = [
'image' => $client->getAsync('/image'),
'png' => $client->getAsync('/image/png'),
'jpeg' => $client->getAsync('/image/jpeg'),
'webp' => $client->getAsync('/image/webp')
];
// Terminate if one request fails
$results = Promise\unwrap($promises);
// Ignore exceptions for certain requests to ensure all requests are sent
$results = Promise\settle($promises)->wait();This code registers multiple asynchronous requests for concurrent execution and specifies whether to ignore exceptions for certain requests to ensure that all requests are sent.
$client = new Client();
$requests = function ($total) use ($client) {
for ($i = 1; $i < $total; $i++) {
$uri = 'https://www.example.com/page/' . $i;
// This uses coroutines
yield function() use ($client, $uri) {
return $client->getAsync($uri.$i);
};
}
};
$pool = new Pool($client, $requests(10), [
// Concurrency
'concurrency' => 5,
'fulfilled' => function ($response, $index) {
echo $res->getStatusCode() . "\n";
},
'rejected' => function ($reason, $index) {
echo $e->getMessage() . "\n";
},
]);
// Initialize the Promise
$promise = $pool->promise();
// Initiate request processing
$promise->wait();This code handles a large batch of requests collectively, similar to the concept of a request pool, with a specified concurrency rate (concurrency) and a unified processing logic for the data in the request pool.
Let’s analyze the constructor of the Pool class.
public function __construct(
ClientInterface $client,
$requests,
array $config = []
) {
// Set the pool size
if (isset($config['pool_size'])) {
$config['concurrency'] = $config['pool_size'];
} elseif (!isset($config['concurrency'])) {
// Default concurrency is 25
$config['concurrency'] = 25;
}
if (isset($config['options'])) {
$opts = $config['options'];
unset($config['options']);
} else {
$opts = [];
}
// Convert the request list into an iterator
$iterable = \GuzzleHttp\Promise\iter_for($requests);
$requests = function () use ($iterable, $client, $opts) {
// Iterate through the request list
foreach ($iterable as $key => $rfn) {
// If it's an implementation of a request, convert it to an asynchronous request
if ($rfn instanceof RequestInterface) {
yield $key => $client->sendAsync($rfn, $opts);
} elseif (
is_callable($rfn)) {
// If it's a closure, call it directly
yield $key => $rfn($opts);
} else {
throw new \InvalidArgumentException('...');
}
}
};
// A promise object that supports iteration
$this->each = new EachPromise($requests(), $config);
}As we can see, in the Pool mode, all request configurations in $opts are the same for every request. Therefore, if each request has custom requirements, Pool mode may not be suitable. However, modifying the source code to cater to individual request customizations deviates from the original purpose of the Pool mode design.
Regardless of the method used, it is observed that they all trigger the wait() method in the end. This is in accordance with the promise specification.
Now, let’s delve into how asynchronous requests are processed.
Do you remember the promise returned by asynchronous requests?
$promise = new Promise(
[$this, 'execute'],
// Close the request based on ID
function () use ($id) { return $this->cancel($id); }
);The wait() method calls [$this, 'execute']. Let’s analyze its implementation. But before that, we need to mention delayed requests specifically.
Delayed Time
For delayed requests, synchronous and stream requests are relatively straightforward to handle; you can simply block them. However, if there are 20 asynchronous requests, among which 10 have varying delay times, handling delayed requests in this scenario requires careful consideration.
In the “Request Processing” section, we discussed that delayed requests are not immediately added to the batch processing request handler. Instead, they are temporarily stored in the $this->delays queue. Delayed requests are only taken out and considered for inclusion in the batch processing request handler when you decide to send the requests. Let’s examine how the blocking time is calculated based on the source code.
public function execute()
{
$queue = P\queue();
while ($this->handles || !$queue->isEmpty()) {
// If there are no active requests and the delayed request queue is not empty, block until the next one.
if (!$this->active && $this->delays) {
usleep($this->timeToNext());
}
$this->tick();
}
}
private function timeToNext()
{
$currentTime = microtime(true);
$nextTime = PHP_INT_MAX;
// Find the smallest delay time in the current delayed request queue.
foreach ($this->delays as $time) {
if ($time < $nextTime) {
$nextTime = $time;
}
}
return max(0, $nextTime - $currentTime) * 1000000;
}execute primarily calls the tick() method.
public function tick()
{
// If the delayed request queue is not empty, handle delayed requests.
if ($this->delays) {
$currentTime = microtime(true);
foreach ($this->delays as $id => $delay) {
// If the delay has reached the expected delay time, start processing.
if ($currentTime >= $delay) {
// Remove it from the delayed task queue.
unset($this->delays[$id]);
// Add it to the batch request handler.
curl_multi_add_handle(
$this->_mh,
$this->handles[$id]['easy']->handle
);
}
}
}
// Execute tasks in the queue.
P\queue()->run();
// Execute requests.
if ($this->active &&
curl_multi_select($this->_mh, $this->selectTimeout) === -1
) {
// See: https://bugs.php.net/bug.php?id=61141
usleep(250);
}
while (curl_multi_exec($this->_mh, $this->active) === CURLM_CALL_MULTI_PERFORM);
// Get request result information and remove successfully processed requests.
$this->processMessages();
}With this, the asynchronous processing flow becomes clear:
- If the delayed request queue is not empty, and there are no active requests, block for the smallest delay time. This ensures that the delayed request queue is consumed at least once with each request. If there are active requests or the delayed request queue is not empty, proceed to step 2.
- Initiate a batch request.
- Get request information and remove successful requests.
- If the request queue is not empty, repeat steps 1-3.
From the above flow, it can be deduced that even if the concurrency is greater than the number of requests, it does not necessarily mean only one request is made. Multiple requests may be made due to retries or delayed requests. Also, based on step 1, it is apparent that non-delayed tasks can also be blocked.
Just like synchronous requests, for asynchronous requests, after each request is processed, the respective then() method is executed to complete result handling.
Stream Requests
Because stream requests are fundamentally based on fopen(), the logic for sending requests is relatively straightforward.
public function __invoke(RequestInterface $request, array $options)
{
// For delayed requests, simply delay them
if (isset($options['delay'])) {
usleep($options['delay'] * 1000);
}
// Key Point 1: Parse the response
return $this->createResponse(
$request,
$options,
// Key Point 2: Send the request
$this->createStream($request, $options),
$startTime
);
}Let’s first look at how the request is sent, with a focus on the configuration handling.
private function createStream(RequestInterface $request, array $options)
{
$params = [];
// Default request parameters are set here
$context = $this->getDefaultContext($request);
// This method mainly calls
// add_proxy, add_timeout, add_verify, add_cert, add_progress, add_debug
// Essentially, it uses custom configurations to override default request parameters
if (!empty($options)) {
foreach ($options as $key => $value) {
$method = "add_{$key}";
if (isset($methods[$method])) {
$this->{$method}($request, $context, $value, $params);
}
}
}
// Custom configurations are also used to override default request parameters
if (isset($options['stream_context'])) {
if (!is_array($options['stream_context'])) {
throw new \InvalidArgumentException('stream_context must be an array');
}
$context = array_replace_recursive(
$context,
$options['stream_context']
);
}
// Resolve the host, supporting forced IP resolution, both v4 and v6
$uri = $this->resolveHost($request, $options);
$context = $this->createResource(
function () use ($context, $params) {
// Create a resource stream here
return stream_context_create($context, $params);
}
);
return $this->createResource(
function () use ($uri, &$http_response_header, $context, $options) {
// Send the request here
$resource = fopen((string) $uri, 'r', null, $context);
$this->lastHeaders = $http_response_header;
// Set the timeout
if (isset($options['read_timeout'])) {
$readTimeout = $options['read_timeout'];
$sec = (int) $readTimeout;
$usec = ($readTimeout - $sec) * 100000;
stream_set_timeout($resource, $sec, $usec);
}
return $resource;
}
);
}From the code, it is evident that HTTPS is enabled by default.
Custom configurations here are no longer a simple array merge operation with the default configurations. This is because modifying a specific configuration may affect other configuration options. Therefore, encapsulation has been applied to several key options: (proxy, timeout, verify, cert, progress, debug).
After all, the powerful fopen function was initially designed to operate on resources. Consequently, its configuration options vary depending on the type of resource. You can see the configuration options for HTTP here.
Next comes the handling of the response. While cURL can easily handle these tasks, when dealing with stream processing, you need to parse the response yourself, essentially performing part of the work that cURL would do.
private function createResponse(
RequestInterface $request,
array $options,
$stream,
$startTime
) {
$hdrs = $this->lastHeaders;
$this->lastHeaders = [];
$parts = explode(' ', array_shift($hdrs), 3);
$ver = explode('/', $parts[0])[1];
$status = $parts[1];
$reason = isset($parts[2]) ? $parts[2] : null;
// Parse headers
$headers = \GuzzleHttp\headers_from_lines($hdrs);
// Parse the response type
list($stream, $headers) = $this->checkDecode($options, $headers, $stream);
// Build a Stream object of Psr7\StreamInterface
$stream = Psr7\stream_for($stream);
$sink = $stream;
$response = new Psr7\Response($status, $headers, $sink, $ver, $reason);
// Callback for on_headers
if (isset($options['on_headers'])) {
try {
$options['on_headers']($response);
} catch (\Exception $e) {
$msg = 'An error was encountered during the on_headers event';
$ex = new RequestException($msg, $request, $response, $e);
return \GuzzleHttp\Promise\rejection_for($ex);
}
}
// Callback for on_stats
$this->invokeStats($options, $request, $startTime, $response, null);
return new FulfilledPromise($response);
}The entire process involves data parsing. The response content is obtained using stream_get_contents and is reflected in the Psr7\StreamInterface instance.
Let’s delve into the on_headers function separately. This function, executed after receiving the response headers, determines how to respond to subsequent operations based on the information in the response headers. When dealing with large response data, it can be used to intercept early to avoid wasting resources.
This setting is effective in all request methods but has more significance in stream processing.
$client->request('GET', 'http://httpbin.org/stream/1024', [
'on_headers' => function (ResponseInterface $response) {
if ($response->getHeaderLine('Content-Length') > 1024) {
throw new \Exception('The file is too big!');
}
}
]);Easter Egg
While analyzing the source code, an unused class, GuzzleHttp\Promise\Coroutine, was discovered. This class represents an implementation of promises but utilizes iterators. Could it possibly indicate the existence of a coroutine-based promise? We eagerly await further developments.